roy > naoya > 基礎プログラミングI > (6)正規表現
(6) 正規表現
[1] 正規表現とは
Windowsでファイルの検索を行ったことがあるだろうか?保存をした場所が分からなくなった場合、ファイル名を手がかりに検索を行う場合がある。正確なファイル名を覚えていれば検索はそれほど難しくはないが、ファイルの名称など何も考えずに決めていることが多いので、あとで探そうと思っても曖昧にしか思い出せないことが多い。
このような場合でも検索が出来るよう、Windowsでは*や?という記号を用いた検索が出来るようになっている。
- ?:任意の1文字をあらわす
- *:任意の文字列をあらわす(何文字でもOK)
例えば、以下のファイルリストより該当するファイルを検索するという状況を考えてみよう。
report1.doc report2.doc report3.doc hoge.xls diary3.doc diary4.doc pict1.jpg pict2.jpg pict3.jpg data.xls star.jpg moon.jpg
ここで、reportと名のつくワードファイル(拡張子がdoc)を検索したい場合はreport?.doc(またはreport*.doc)が検索キーワードになる。
pから始まるjpgファイルであれば、検索キーワードp*.jpgとなる。
ファイル名を覚えている場合には、「star.jpg」などももちろん検索キーワードになる。
検索をするときに、そのデータに含まれる文字列の一部やパターンを使うことがある。こうした検索パターンを表現するために利用する表記法を正規表現と呼ぶ。
[2] Rubyにおける正規表現
「TAKESHI」と「TAKESI」を探したい場合、Rubyでは次のように正規表現を書く。
/TAKESH?I/
Rubyでは?は直前のHはあってもなくてもよいという指定になる。これで「TAKESHI」と「TAKESI」のどちらでも該当する。なお、TAKESH?Iの両側に//があるが、//はこれが正規表現であることを示すRubyの記法である。
次に、「スガハラ」さんと「スガワラ」さんを探す際の正規表現を確認しよう。
/スガ[ハワ]ラ/
[]の中に何文字か入れると、これらのうちのいずれかが含まれればよいという指定になる。正規表現であることを示すため//でくくっている。
なお、正規表現を書く際に使用する?や[]などの特殊文字をメタ文字と呼ぶ。
[3] 正規表現を用いた検索
指定したファイルから該当する文字列を含む行を検索するプログラムを作り検索してみよう。
まず、下記の架空の名簿をmeibo.txtという名前をつけて保存する(プログラムを作成する時と同じようにemacsに貼り付けて保存)。
丘本秋子 オカモトアキコ 酒田市 OKAMOTO Akiko 高梁缶 タカハシカン 真室川町 TAKAHASHI Kan 仁科牧子 ニシナマキコ 最上町 NISHINA Makiko 藤嶌楓 フジシマカエデ 庄内町 HUJISHIMA Kaede 町村利郎 マチムラトシロウ 鶴岡市 MACHIMURA Toshiro 市川週一 イチカワシュウイチ 遊佐町 ICHIKAWA Shuichi 多村数馬 タムラカズマ 西川町 TAMURA Kazuma 砂糖真琴 サトウマコト 山形市 SATO Makoto 藤嶋丸子 フジシママルコ 東根市 FUJISIMA Maruko 嶋田多香子 シマダタカコ 天童市 SHIMADA Takako 齋藤由 サイトウユウ 大江町 SAITO Yu 高橋麹 タカハシコウジ 村山市 Takahasi Koji 渡部すず ワタベスズ 米沢市 WATABE Suzu 渡辺勇次 ワタナベユウジ 小国町 WATANABE Yuji 藤島真希 フジシママキ 寒河江市 FUJISHIMA Maki
次に、以下のプログラムをkensaku.rbという名前をつけて保存する。
#!/usr/koeki/bin/ruby
# -*- coding: utf-8 -*-
while line=gets
if /sai?to/i =~ line
print line
end
end保存をしたら実行してみる。ファイルを読み込んで実行するので、プログラム名のあとにmeibo.txtを指定する。
sime{c11xxxx}%chmod +x kensaku.rb[Return]
sime{c11xxxx}%./kensaku.rb meibo.txt[Return]
砂糖真琴 サトウマコト 山形市 SATO Makoto
齋藤由 サイトウユウ 大江町 SAITO Yu
続いてプログラムの各行について解説する。
while line=gets
getsメソッドはプログラム実行時にファイルを指定すると、そのファイルから1行ずつ読み込みを行う。ここでは、meibo.txtより1行ずつ読み込み変数lineに代入しながら繰り返し処理を行っている。meibo.txtは15行あるので、15回繰り返され、16回目になると読み込むデータがなくなるので繰り返しから抜ける。
if /sai?to/i = ~line
この行で読み込んだ行が検索パターン(正規表現)にマッチしているかどうか判定を行う。正規表現にマッチしているかどうかは
/正規表現/ =~ 文字列
と表記する。=~は「正規表現にマッチする」という比較演算子である。反対に「正規表現にマッチしない」は!~とあらわす。
if /sai?to/i = ~lineでは、検索パターンは「sai?to」である。これは「saito」もしくは「sato」をあらわす。//の後ろにあるiは大文字と小文字を区別しないという意味を付加するもので、必要に応じてつけたり、つけなかったりする。iをつけない場合は「sato」はマッチするが、「SATO」「Sato」「sAtO」などはマッチしなくなる。
print line
lineという変数には、ファイルから読み込んだ行が入っている。上記の条件に合致する場合に、その行が出力される。
end
ifに対応するend。
end
whileに対応するend。
正規表現を用いたプログラムに関するまとめ
- 外部ファイルを読み込んでプログラム内で用いる場合、ktermでruby プログラム名 読み込むファイル名として実行する。
- 実行時に外部ファイルを指定した場合、getsメソッドはキーボードの入力を読み込むかわりにファイル内容を読み込む。
- ファイルからの読み込み時は\nまでを1つのデータとして扱う。
- =~は正規表現にマッチするという比較演算子、!~は正規表現にマッチしないという比較演算子
- 正規表現のパターンの後ろのiは大文字と小文字を区別しないという意味。
[4] 正規表現のオプション
/正規表現/の後ろにiは大文字と小文字の区別をしないというオプションであるが、これは半角英数字を検索対象とする場合に有効なオプションである。日本語の場合はオプションをつける必要はない。自動的にUTF-8文字列として照合される(プログラムの2行目にcoding: utf-8と書いているため)。
正規表現のオプション
- i:アルファベットの大文字と小文字を区別しない
[5] 正規表現によるマッチング(メタ文字)
通常の文字によるマッチング
正規表現によるパターンが英数字や日本語のみで書かれている場合、検索する文字列内にその文字が含まれていればマッチする。以下にサンプルを示す。正規表現にマッチする文字列は黄色の網掛けで示し、マッチしている部分を赤色で示す。
正規表現:/ABC/(意味:ABCを含む文字列)
#=> ABC、 ABCDEF、 123ABC、 A1B2C3、AB、abc
バックスラッシュを使ったメタ文字
\s(バックスラッシュスモールエス):空白文字をあらわす。空白、タブ、改行文字とマッチする。
正規表現:/ABC\sDEF/(意味:ABCとDEFの間に空白が一つある文字列)
#=> ABC DEF、 ABC\tDEFGH、 123ABC\nDEFG、 ABCDEF
\S(バックスラッシュラージエス):空白以外をあらわす。
正規表現:/ABC\SDEF/(意味:ABCとDEFの間に空白以外の文字が一つある文字列)
#=> ABC3DEF4GHI、 012-ABC-DEF、 ABC DEF、 ABCDEF
\d(バックスラッシュスモールディー):0から9までの数字とマッチする。
正規表現:/\d\d\d-\d\d\d\d/(意味:ハイフンの手前に数字が3桁、後ろに4桁あるもの)
#=> 012-3456、 01234-012345、 ABC-DEFG、 012-21
\D(バックスラッシュラージディー):0から9までの数字以外とマッチする。
正規表現:/\D\d\d\d\d\d\d\D/(意味:数字以外の文字の間に数字が6桁並んでいるもの)
#=> c106999a、 c1068887
\w(バックスラッシュスモールダブリュー):英数字と_(アンダーバー)にマッチする。
正規表現:/\w\w\w/(意味:英数字が3つ連続で続いている文字列)
#=> ABC、 abc、 012、 AB C, AB\nC
\W(バックスラッシュラージダブリュー):英数字と_(アンダーバー)以外にマッチする。
正規表現:/A\WB/(意味:AとBの間が英数字以外の文字列)
#=> A C、 A-C、 ABC、A9C
\A(バックスラッシュラージエー):文字列の先頭にマッチする。^との違いは、^は画面上に出力されている状態で先頭にあればマッチするが、\Aはひとかたまりの文字列の先頭であるかどうかを見る。具体的には、123\nABCは文字列の途中に改行文字が入っているが、/^ABC/はマッチするのに対し、/\AABC/はマッチしない。
正規表現:/\AABC/(意味:先頭がABCである文字列)
#=> ABC、 ABCDEF、 012ABC、 012\nABC
\Z(バックスラッシュラージゼット):文字列の末尾にマッチする。$との違いは、$が画面上に出力されている状態で末尾にあればマッチするが、\Zはひとかたまりの文字列の末尾であるかどうかを見る。具体的には123\nABCは文字列の途中に改行文字が入っているが、/123$/はマッチするのに対し、/123\Z/はマッチしない。
正規表現:/ABC\Z/(意味:末尾がABCである文字列)
#=> ABC、 012ABC、 ABCDEF、 012\nABC、 ABC\nDEF
\b(バックスラッシュスモールビー):単語の境界にマッチする。例えば/cat/で検索すると、concatenateやcategoryもマッチするが、\bcat\bにすると、単語として独立したcatしかマッチしない。
正規表現:/\bdog\b/(意味:dogという単語を含むもの)
#=> dog、 hot dog、 dogberry
行頭(^)と行末($)のマッチング
ABCから始まる文字列や、最後がABCで終わっている文字列を検索する場合は、「^」や「$」といった特殊な文字(メタ文字)を使用する。「^」は行頭マッチング、「$」は行末マッチングをあらわす。
正規表現:/^ABC/(意味:ABCで始まる文字列)
#=> ABC、 ABCDEF、 123ABC
正規表現:/ABC$/(意味:ABCで終わる文字列)
#=> ABC、 ABCDEF、123ABC
マッチさせたい文字を範囲で指定する
イトウもしくはゴトウのように「イかゴ」のどちらかを含むという条件を指定する場合、マッチさせたい文字の集合を[]で囲む。[]内のどれかが該当すればマッチすることになる。
正規表現:/[ABC]/(意味:A、B、Cのいずれかを含む文字列)
#=> DNA、 Book、 BAC、 Cat、 DOT
正規表現:/[CBA]/(意味:A、B、Cのいずれかを含む文字列。上と同じ)
#=> DNA、 Book、 BAC、 Cat、 DOT
「大文字のアルファベットが含まれていればなんでもOK」というような正規表現を指定する場合、○-○というようにハイフンを使って範囲で指定することができる。
正規表現:/[A-Z]/(意味:アルファベットの大文字を含む文字列)
#=> 028A、 Book、 Cat、 dog、075、6-4
正規表現:/[a-z]/(意味:アルファベットの小文字を含む文字列)
#=>028A、 Book、 Cat、 dog、 075、6-4
正規表現:/[0-9]/(意味:数字を含む文字列)
#=> 028A、 Book、Cat、dog、 075、 6-4
正規表現:/[A-Za-z_-]/(意味:アルファベットとアンダーバーとハイフンを含む文字列)
正規表現:/[ぁ-ん]/(意味:ひらがなを含む文字列「ぁ」は小文字)
正規表現:/[亜-腕]/(意味:漢字を含む文字列。ただし第一水準のみ)
ハイフンは範囲を示すために使用するので、ハイフン自体を検索対象の文字列としたい場合は、最初か最後に書かなければならない。
なお行頭マッチングで使用した^は[]内で使用するとそこで指定されたもの以外の文字という意味になる。例えば、[^ABC]はA、B、C以外の文字ということになる。
正規表現は組み合わせて使用することができる。ここまでに出てきたものを組み合わせると以下のようなものを作ることができる。
正規表現:/a[ABC]c/(意味:aとcの間にA、B、Cのいずれかがある文字列)
#=> aBc、 1aBcDe、 abc
正規表現:/a[^A-C]c/(意味:aとcの間がA、B、C以外の文字である文字列)
#=> aBcabc、 a0c、 malcolm、 aCc
正規表現:/[0-9][A-Z]/(意味:数字の次に大文字のアルファベットが続く文字列)
#=> 0A、 000AAA、XBJ254
正規表現:/[^A-Z][A-Z]/(意味:アルファベットの大文字以外の文字の次にアルファベットの大文字が続く文字列)
#=> aA2B3C、 NH068A
任意の文字とのマッチング
.(ピリオド):任意の1文字にマッチする。ピリオド1つなら1文字の文字列、3つなら3文字の文字列をあらわす。
正規表現:/A.C/(意味:AとCの間に何か一文字ある文字列)
#=> ABC、 012A3C456、 AAC、 AC、 ABBC、 abc
正規表現:/aaa.../(意味:aaaの後に何か三文字続く文字列)
#=> 00aaabcde、 aaabb
繰り返し
*:直前の文字の0回以上の繰り返しにマッチする。
正規表現:/AB*C/(意味:Cの前にBが0個以上ある)
#=> ABBC、 AC、 ADC
正規表現:/A.*C/(意味:AとCの間に何かが何個あってもいいし、なくても良い)
#=> AB012C、 AB CD、 ACDE
+:直前の文字の1回以上の繰り返しにマッチする。
正規表現:/A+C/(意味:Cの前にAが1個以上ある)
#=> AAAC、 BAC、 BC、 AAAB
正規表現:/A.+C/(意味:AとCの間に何かが1個以上ある)
#=> AB012C、 AB CD、 ACDE
?:直前の文字の0回または1回の繰り返しにマッチする。
正規表現:/BAA?C/(意味:Cの前にAが1個または2個ある)
#=> BAC、 BAAC、 BAAAC
正規表現:/A.?C/(意味:AとCの間に何もない、もしくは1文字ある)
#=> ACDE、 ABCDE、 AB012C、 AB CD
()と繰り返し
():*+?と組み合わせて使用することで,1文字単位での繰り返しではなく、複数の文字列の繰り返しにマッチする。
正規表現:/(ABC)+/(意味:ABCが1回以上繰り返されている)
#=> ABC、 ABCABC、 ABCABCABC、 BCA
正規表現:/HOTO(TO)?GISU/(意味:TOが0回もしくは1回)
#=> HOTOTOGISU、 HOTOGISU、 HOTOTOTOGISU
選択
|:いくつかの候補の中からどれか1つに当てはまるものにマッチする。
正規表現:/(sakura|kashiwa)mochi/(意味:mochiの前にsakuraもしくはkasiwaがある)
#=> sakuramochi、 kasiwamochi、 yakimochi
正規表現の特殊文字
\:ピリオド、[]、?、*、+、^、$、|、()などのメタ文字として使用されている文字を検索対象としたい場合は手前にバックスラッシュをつけ、\.、\[、\]、\?、\*、\+、\^、\$、\|、\(、\)とする。バックスラッシュを検索対象とする場合も\をつけ\\とする。
[6] 複雑な正規表現のパターンを作る
メタ文字は組み合わせて使用することができる。幾つか例を示す。
- /^...X\d\d/:先頭から4文字目がXでその後に数字が2つ続いている文字列
- /^[A-Z].+rb$/:先頭が大文字でその後は何でも良くて最後にrbがついている文字列
- /^\S\S\s+/:先頭が2文字でその後が空白になっている文字列
[7] 出席課題
meibo.txtにおいて以下の検索を行うための正規表現を考えてみよう。実際にkensaku.rbの正規表現を書き換えて実行し、望んだ結果が出ることを確認しよう。
- 市ではなくて町に住んでいる人にマッチする正規表現
- 名前に「子」がつく人で市に住んでいる人にマッチする正規表現
- 名前のローマ字表記が5文字(例えばAkiko)の人にマッチする正規表現
制限時間は10分。完成しない場合は、途中まででも構わないので実行し、結果をメールで送ること。出席点は2点。提出要領は下記の通り。
- 提出先:課題提出用メールアドレス
- メールのSubject:ruby06
- 本文の構成:1行目で学籍番号、氏名を記載する。2行目以降に3つの問題の答え(正規表現)を書く。時間があれば、各正規表現のパターンについて説明を加えてみる。
[8] 正規表現のパターンをキーボードから入力
[9] 正規表現の後方参照への導入
正規表現を用いることで、これまで出来なかったことが出来るようになる。前回まで、何度かファイルからデータを読み込んで処理をするレポート課題を実施してきた。while line = getsという構文を用いることで、ファイルから1行ずつ読み込んで処理をすることができた。
これまで使用してきたファイルには1行に1つしかデータしかなかったため問題は生じなかったが、
英語 国語 数学
95 32 76
67 87 42
29 76 88
:
上のケースのように、1行に複数のデータが記載されている場合は、1行ずつ読み込むと3つのデータが全て1つの変数に代入されてしまうため、合計などを計算することが出来なくなる。この場合、読み込んだ行から特定の部分だけを切り取って利用することができれば都合が良い。
正規表現の後方参照という機能を用いると、特定部分を切り取ることが可能となる。
[10] 正規表現の後方参照
学籍番号と得点が記された以下のファイルがある(data.txt)。このファイルから学籍番号と得点を読み込んでそれぞれデータとし、平均点および各人の得点の平均からの差を算出してみよう。
学籍番号 点数 c110001 45 c110002 52 c110003 38 c110004 60 c110005 44 c110006 67 c110007 50 c110008 57 c110009 41 c110010 45
まずは、前回までと同じようにファイルから1行ずつ読み込むプログラムを書いてみよう。話を単純化するため、単に読み込んだデータを表示するだけのプログラムとする(reg_ex1.rb)。
#!/usr/koeki/bin/ruby
# -*- coding: utf-8 -*-
while line=gets
print line
endこれを実行すると、以下のように読み込んだ行がそのまま表示される。変数lineには学籍番号と得点という2つのデータが代入されていることが分かる。
sime{c11xxxx}% chmod +x reg_ex1.rb[Return]
sime{c11xxxx}% ./reg_ex1.rb data.txt[Return]
学籍番号 点数
c110001 45
c110002 52
c110003 38
:
次に、学籍番号だけを取り出してみよう(reg_ex2.rb)。
#!/usr/koeki/bin/ruby
# -*- coding: utf-8 -*-
while line=gets
if /(\S+)\s+\d+/ =~ line
number = $1
print number
end
endこのプログラムを実行してみると、確かに学籍番号だけが表示される。先頭行の「学籍番号 点数」の部分も表示されない。
sime{c11xxxx}% chmod +x reg_ex2.rb[Return]
sime{c11xxxx}% ./reg_ex2.rb data.txt[Return]
c110001
c110002
c110003
:
このプログラムのポイントは正規表現の行とその下に続く2行である。順番に確認しよう。
if /(\S+)\s+\d+/ =~ line
プログラムを読み込むとファイルから1行ずつ読み込みlineに代入する。そしてこの行で読み込んだデータが正規表現にマッチするか判定が行われる。ここで使用しているメタ文字は次の4種類である。
- \S:空白以外にマッチ
- \s:空白にマッチ
- \d:数字にマッチ
- +:1回以上の繰り返しにマッチ
これらのメタ文字で表現されている正規表現のパターンと読み込んだデータの対応関係は下の図の通りであり、空白以外が1文字以上(\S+)空白が1つ以上\s+数字が1桁以上\d+という構成は、学籍番号と得点というデータの構成に完全にマッチしていることがわかる。
データから一部を取り出して使う場合には、前提条件としてこのように読み込んだ行に完全にマッチする正規表現を書く必要がある。なお、1行目の「学籍番号 点数」はこの正規表現にマッチしないので、その後の処理が行われない。
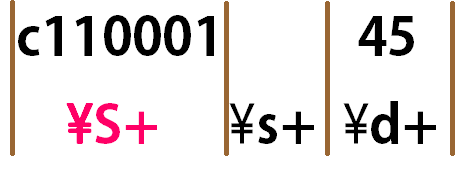
ところで、/(\S+)\s+\d+/には1箇所()がついている。正規表現のパターンを書く際に()をつけておくと、その()内のメタ文字にマッチした部位を後で取り出すことができる。これが後方参照である。
後方参照とは
後方参照は、正規表現にマッチしたデータから特定の部位を取り出す方法である。正規表現を記述する際、()を使って記述しておくと、()でくくられた部分にマッチした部位を、()の順番に応じて$1、$2のように$数字の形で取り出すことができる。なお、この形式で取り出した場合、値の型は文字列となる。
()内に書かれている\S+にマッチするのは学籍番号である。()が1つなので、これは$1で取り出すことができる。
number = $1
$1とすると学籍番号を取り出すことが出来るので、これを変数numberに代入している。
print number
numberに代入されている学籍番号を表示している。
正規表現の後方参照を用いたデータ処理
話をもとに戻そう。ここでは、data.txtから学籍番号と得点を読み込んで、平均点と各自の得点の平均点からの差を表示する。つまり利用するのは「学籍番号」と「点数」という2つのデータである。先ほどは後方参照を使って学籍番号だけを取り出したが、今度は点数も取り出す必要がある。また、平均点を計算したあとで各自の点数と平均点の差を調べる必要があるので、配列を使用する必要がある。これらを踏まえて作成したプログラム(reg_ex3.rb)を見てみよう。
#!/usr/koeki/bin/ruby
# -*- coding: utf-8 -*-
#初期設定
number = [] #学籍番号を代入する配列
score = [] #得点を代入する配列
sum = 0 #合計を代入する配列
n = 0 #配列に使用するインデックス
i = 0 #配列に使用するインデックス
#学籍番号と得点の読み込みと合計の計算
while line = gets
if /(\S+)\s+(\d+)/ =~ line
number[n] = $1
score[n] = $2.to_f
sum += $2.to_f
n += 1
end
end
#個々人の得点と平均点との差
average = sum / n
print"- 学籍番号 ------ 得点 ---- 差 - \n"
while i < number.length
printf(" %-10s \t %3d \t %6.1f\n",
number[i],score[i],score[i]-average)
i += 1
endこのプログラムを実行すると以下の結果が得られる。
sime{c11xxxx}% chmod +x reg_ex3.rb[Return]
sime{c11xxxx}% ./reg_ex3.rb[Return]
- 学籍番号 ------ 得点 ---- 差 -
c110001 45 -4.9
c110002 52 2.1
c110003 38 -11.9
c110004 60 10.1
c110005 44 -5.9
c110006 67 17.1
c110007 50 0.1
c110008 57 7.1
c110009 41 -8.9
c110010 45 -4.9
このプログラム中で使用されている正規表現のパターンは/(\S+)\s+(\d+)/である。(\S+)が学籍番号にマッチし、\s+はその後のスペースに、(\d+)は得点にそれぞれマッチする。その後、
number[n] = $1
score[n] = $2.to_f
sum += $2.to_f
n += 1
$1、$2で()にマッチした部位を取り出し、それぞれ配列に代入している。$1は学籍番号、$2は得点に相当する。代入する際にはnumber[n]やscore[n]などの配列を使用している。インデックスはnであり、nの初期値は冒頭で0を代入しているため、1回目はnumber[0]やscore[0]に代入される。while-endの繰り返しを行うたびにn+=1をしているため、インデックスに使用するnは繰り返しを行う中で、1、2、3、・・・と1ずつ増加する。
後方参照の定義でも述べたように、$1、$2の形で取り出したときの値の型は文字列になる。このままでは合計得点や平均点を算出することができないため、score[n] = $2.to_fというように$2の後ろに型変換メソッドをつけている。to_iではなくto_fとしているのは、平均点や、平均点からの差異を計算する際に小数点以下の値がでてくる可能性があるためである。to_iとすると、小数点以下を切り捨ててしまうので、結果がおかしくなってしまう。
[11] レポート課題
問題1~3のいずれかを選んで実施しなさい(report5.rb)。
問題1(7点満点):基礎プログラミングIVという架空の授業におけるAさんの出欠・レポート点のデータを読み込んだ上で、出席点とレポート点をあわせた合計得点を計算し、合計得点と成績評価を表示せよ。
授業の出欠とレポート点(問題1用)(result1.txt)
- 出欠:出席2点、遅刻1点、欠席0点として得点を記載
- レポート:得点を記載。0点は課題がそもそもないか、未提出の場合
問題2(8点満点):基礎プログラミングIVという架空の授業におけるAさんの出欠・レポート点のデータを読み込んだ上で、出席点とレポート点をあわせた合計得点を計算し、合計得点と成績評価を表示せよ。
授業の出欠とレポート点(問題2用)(result2.txt)
- 出欠:出席2点、遅刻1点、欠席0点とする
- レポート:なし、未提出は得点を与えない
成績評価の基準はいずれも、以下の通りとする。
- 秀:90点以上
- 優:80点以上、90点未満
- 良:70点以上、80点未満
- 可:60点以上、70点未満
- 不可:60点未満
問題3(9点満点):A大学では一般入試として7科目(英語、国語、数学I、世界史、日本史、現代社会、理科総合)を実施している。このうち英語は必須であり、残りの6科目については何科目受験しても良い。そして、英語+受験をした科目のうちで得点の高かった2科目の計3科目の合計得点で合格の有無が判定される。
以下は、A大学を受験した1万人の受験者の各科目の得点を示したファイルである。このファイルを読み込み、合格者となる3教科の合計得点が高い上位20名の受験番号と合計得点を表示するプログラムを作成せよ。
1万人のデータ(問題3用)(result3.txt)
- 各行の先頭は受験番号
- 受験番号の右に受験した科目の得点が入力されている
- 各項目の間は,(カンマ)で区切られている
- ,,というカンマの連続は、当該科目が未受験であることを表す(例:t00001は現代社会が未受験)
- ヒント
- このプログラムは後期に学ぶハッシュを使うとそれなりに簡単に書けるが、ハッシュは使わず配列で書くこと
提出要領
- 提出先:課題提出用メールアドレス
- 提出期限:第1提出期限、第2提出期限を設定
- メールのSubject:report05
- 本文の構成:1行目で学籍番号、氏名を記載する。2行目以降は下記の構成とする
- 何番を実施したか
- 作成したプログラム
- プログラムの実行結果
- プログラムの説明
- 感想
- 参考文献
- ファイルの添付(プログラムのみ)
採点要領
- 採点基準:期限内提出点(2点)、メールの体裁(1点)、プログラム(2点/3点/4点)、プログラムの説明(2点)
- プログラムの説明は、正規表現と後方参照の部分を中心に行うこと。
- わかりにくい説明や、Webページを単にコピー&ペーストしただけの説明は減点することがある。一度読み直してから提出すること。
- 他人のレポートを丸写しした場合は、写した側、写させた側共に0点とする。
- 驚異的に良くできているレポートについては満点を超える得点をつけることがある。
- よくできていたレポートは、他の人の参考になるよう、本人が特定できないような形で掲載する。掲載してほしくない場合はメールでの課題提出時にその旨記載すること。