
(10) 06/19の授業内容:コンピュータの内部表現
2進数と16進数
コンピュータ内部では、文字も数字も写真も音楽も全て1と0の2種類の数字に置き換えられて保存されている。1と0の2種類の情報であれば、スイッチのオン/オフや、磁極の向き、光の点滅で表現することが可能となる。我々が日常的に使用している10進数をコンピュータでそのまま取り扱うことを考えた場合、10種類の情報の表現方法を考えなければならず、装置の複雑化、大型化を招くことになる。
2進数は0と1の2種類の数字のみを使用するため、0の次は1、1の次は1桁繰り上がって10になる。以下に10進数との対応関係を示す。右側には16進数というのもある。2進数は2種類の数字のみで表現するために桁数が大きくなりやすい。コンピュータにとっては桁が多くても全く問題はないが、人間は読み間違いをする可能性がある。16進数は2進数を4桁ごとに区切って0000から1111を0からfに置き換えたものである。
| 2 進 数 | 10 進 数 | 16 進 数 |
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 10 | 2 | 2 |
| 11 | 3 | 3 |
| 100 | 4 | 4 |
| 101 | 5 | 5 |
| 110 | 6 | 6 |
| 111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | 10 | a |
| 1011 | 11 | b |
| 1100 | 12 | c |
| 1101 | 13 | d |
| 1110 | 14 | e |
| 1111 | 15 | f |
| 10000 | 16 | 10 |
Rubyでの2進数、10進数、16進数取り扱い
Rubyでは、数値の先頭につける記号でその値が何進数であるかを指定する。
- 接頭語なし:10進数(例えば,10,25)
- 接頭語0b:2進数(例えば,0b1001,0b111101)
- 接頭語0x:16進数(例えば0x1a1,0xf)
なお、何進数で指定をしても、一旦読み込まれれば全て内部では10進数で計算される。出力する際に何進数とするかは、printfの書式制御文字により指定可能である。
- %d:10進数
- %b:2進数
- %x:16進数
出席課題
以下のプログラムは好きな数字の入力を求め、進数の変換を行うものである。emacsに貼り付けて保存をした後で(change.rb)、その下にある5つの数字を指定した進数に変換した結果をメールで送信する。ただし、このプログラムにはエラーがあり、このままでは上手く実行できない。エラーを修正した後で実行すること。
#!/usr/koeki/bin/ruby
STDERR.print "好きな数字を入力してください"
number = STDIN.gets.chomp!
STDERR.print "何進数に変換しますか(1:2進数、2:10進数、3:16進数)"
choice = STDIN.gets.chomp!.to_i
if choice = 1
printf ("2進数だと%bです\n",number)
elsif choice = 2
printf ("10進数だと%dです\n",number)
elsif choice = 3
printf ("16進数だと%xです\n",number)
else
print "それは無理な相談ですね\n"
end
- 256を2進数で表示
- 0xfaceを10進数で表示
- 0b1111101011001110を10進数で表示
- 65535を16進数で表示
- 0x123456789abcdeを2進数で表示
制限時間は5分。出席点は2点。提出要領は下記の通り。
- 提出先:naoya@e.koeki-u.ac.jp
- メールのSubject:学籍番号-ruby10
- 本文の構成:1行目で学籍番号、氏名を記載する。2行目以降でまずプログラムのどこを修正したかを述べ、その後で1〜5の解答を記す。
Tips:emacsでの日本語入力のオンオフはCtrl-oです
Tips:Mewによるメールの送り方はMewコマンドを参照
2進数と10進数の変換
10進数を2進数へ
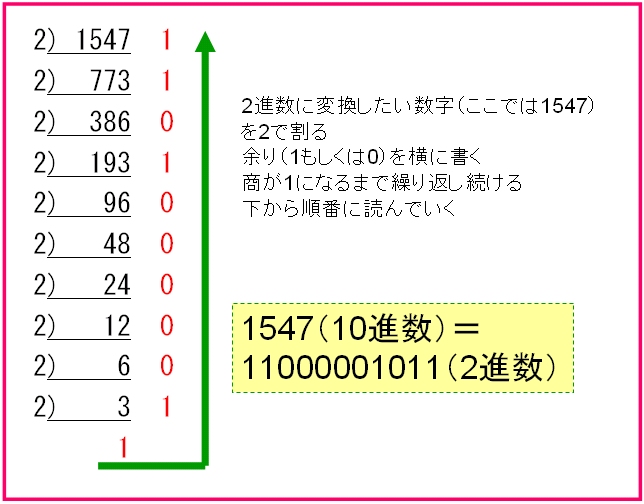
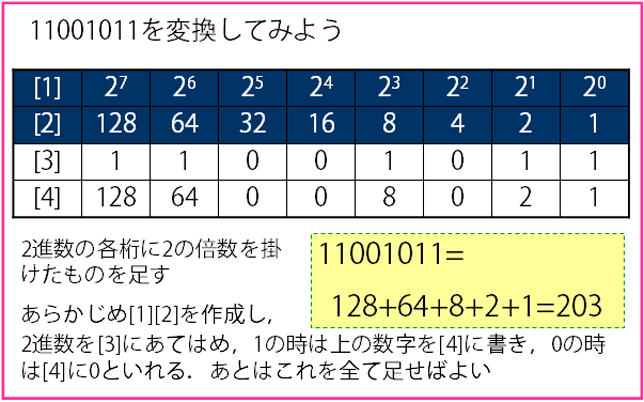
2進数を10進数へ
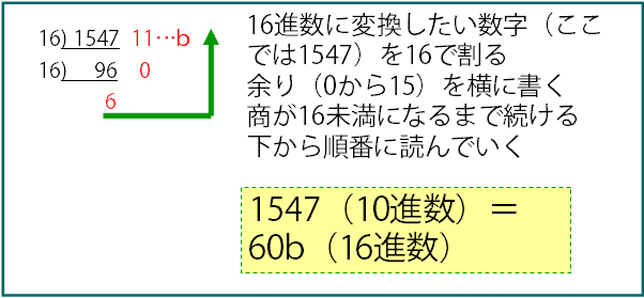
16進数と10進数の変換
10進数を16進数へ
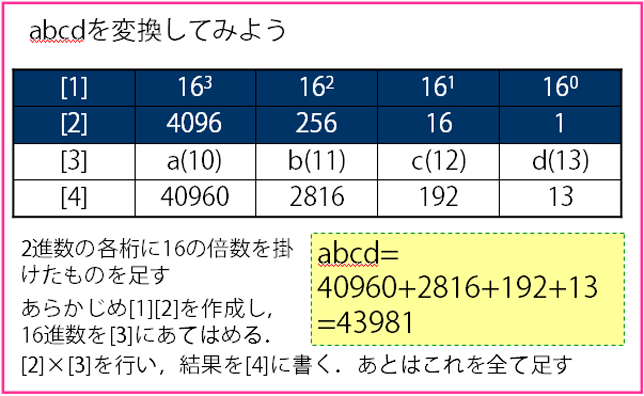
16進数を10進数へ
ASCIIコード
コンピュータ内では文字が1と0の組み合わせに置き換えられて保存されていることはすべに述べたが、この数字の配列と文字の対応表のことを文字コードという。
半角英数字は、0-9の数字、A-Zの大文字のアルファベット、a-zの小文字のアルファベット、?#$%@などの記号により構成されている。これだけの情報を1と0の組み合わせで表現するためにはある程度の桁数がなければならない。桁数と表現できる種類の関係は下記の通りである。
- 1桁:21=2
- 2桁:22=4
- 3桁:23=8
- 4桁:24=16
- 5桁:25=32
- 6桁:26=64
- 7桁:27=128
- 8桁:28=256
- 9桁:29=512
- 10桁:210=1024
- 11桁:211=2048
- 12桁:212=4096
- 13桁:213=8192
- 14桁:214=16384
- 15桁:215=32768
- 16桁:216=65536
半角英数字は2進数8桁で表現されている(ただし先頭の1桁は使用していないので実際には7桁)。半角英数字の文字コードのことをASCIIコードという。一方、日本語は漢字が含まれるため8桁では表現できない。日本語を表現するためには1文字当たり16桁の2進数が用いられる。日本語の文字コードはJIS、Shift-JIS、EUCが用いられている。つまり、2進数と文字の対応表が3種類ある。時折文字化けで見られないWebページがあったり、emacsで作成したプログラムのうち日本語部分がおかしくなっている場合があったりする。これは文書やプログラムを作成したときの文字コードと表示をするときの文字コードが一致していないためである。UNIX環境ではEUCを用いる。
ASCIIコードの表は以下の通りとなる。ここでは16進数での文字コード表記となっている。2進数で表現しても良いが、桁数が多くなるため読み間違える可能性が生じる。
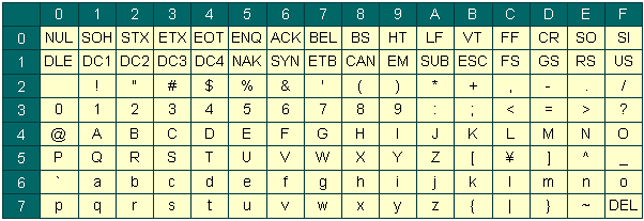
行方向(左側)が10の位、列方向(上側)が1の位になる。例えばAは41になる。Rubyでは16進数は0xをつけるのでAは0x41と表現できる。
0行と1行(0x00〜0x1F)は制御文字をあらわす。主に端末のコントロールをするもので代表的なものとして以下を挙げることができる。
- 0x00 NUL:空文字(文字列の終端をあらわすことが多い)
- 0x07 BEL:端末のベルを鳴らす
- 0x08 BS:バックスペース
- 0x09 HT:タブ
- 0x0A LF:改行
- 0x1B ESC:エスケープ
文字列と文字コード
制御文字の中にはキーボードから入力できないものがある。プログラムの中で制御文字を使用したい場合は文字コードで指定する。
文字コードに対応する文字を出力
%c:printfの書式制御文字の%cは、文字コードに対応する文字を出力する。
printf ("%c", 0x07)
とすると、文字コード0x07すなわちBELが出力され、端末のベルがなる(がスピーカーがついていないと音はならない)。
文字に対応する文字コードを出力
特定の文字の文字コードを知るためには?文字とする。例えばプログラム中で?Qとすれば、それはQの文字コード(0x51)を書いたのと同じことになる。さらに、これをprintfの制御文字である%x(16進数)で表示すれば、対応する文字コードが明らかになる。
しかし,この方法では1文字の文字コードを調べるのは簡単でも、文字列を構成する各文字の文字コードを調べるのはやや面倒である。文字列"Koeki"を構成する"K""o""e""k""i"の各文字の文字コードを調べることを考えてみよう。ここでは配列のときと同じように[]を利用すると簡単に取り出すことができる。
printf ("%x\n", "Koeki"[i])
上記のようにインデックスにiを使用し、初期値を0とした上で、whileの繰り返しの中でiの値を1ずつ変更していけば構成する文字の文字コードを全て明らかにすることができる。もちろん下記のように文字列を変数に代入しても同じことである。これによりキーボードから入力した任意の文字列を構成する文字の文字コードを調べることができる。
a = "Koeki"
printf ("%x\n", a[i])
レポート課題
以下の5問を実施する。
- 0x1d8f(16進数)を10進数に変換せよ(計算過程を示すこと)
- 0b11001101010(2進数)を10進数に変換せよ(計算過程を示すこと)
- 0x167 + 0x35の計算を行った結果を2進数で示せ(計算過程を示すこと)
- 0x167 + 0x35の計算を行った結果を10進数で示せ(計算過程を示すこと)
- キーボードから入力した任意の半角英数字で構成される文字列を文字コード(16進数)に変換して出力するプログラムを作り、ローマ字で書いた自分の名前を全て文字コード(16進数)で表記せよ
問1から問4の計算過程のうち例えば、10進数を2進数に変換する場合の計算過程は以下のように書くことができる。
2) 100 0
----
2) 50 0
----
2) 25 1
----
2) 12 0
----
2) 6 0
----
2) 3 1
----
1
- 提出先:naoya@e.koeki-u.ac.jp
- 提出期限:6/25(日)23:59(1限履修者)·7/2(日)23:59(2限履修者)
- メールのSubject:学籍番号-kadai08
- 本文の構成:1行目で学籍番号、氏名を記載する。2行目以降は下記の構成とする
- 問1の計算過程と解答
- 問2の計算過程と解答
- 問3の計算過程と解答
- 問4の計算過程と解答
- 問5のプログラム
- 問5のプログラムの説明
- 問5の実行結果
- 感想
- 採点基準:期限内提出点(2点)、メールの体裁(1点)、問1〜問4(各1点)、問5はプログラムが1点、説明が1点とする。問1〜問4は計算過程が示されていない場合は減点する。
- 驚異的に良くできているレポートについては満点の8点を超える得点をつけることがある。
- よくできていたレポートは、他の人の参考になるよう、本人が特定できないような形で掲載する。掲載してほしくない場合はメールでの課題提出時にその旨記載すること。
Tips:emacsでの日本語入力のオンオフはCtrl-oです
Tips:ktermでのプログラムの実行結果をメールに貼り付けるには、コピーしたい箇所をマウスで選択し、emacs(Mew)上でマウスの真ん中ボタンをクリックする
Tips:Mewによるメールの送り方はMewコマンドを参照