var())と標準偏差(sd())の結果を利用する。
平均を
RのCUIを主に利用する。 より詳しい用法を知りたい場合は R-Tips を参照する。
起動はコマンドラインで R で,
終了はRのプロンプトから q() 関数を呼び出す。
R (起動) q() (終了) Save workspace image? [y/n/c]:
終了時に,作業に用いた変数などの状態を保存するか聞いて来る。
保存して終了するなら y を,保存しないなら n,作業を続けるなら c
を入力する。q() の代わりにデータ入力終端を表す
C-d をタイプしてもよい。
以後,コマンドラインへのコマンド入力は「% 」プロンプトで,
Rへの式入力は「> 」プロンプトで示す。
式を評価した結果は変数に格納できる。変数名は最初の文字が
英字,2字目以降は英数字のものが利用できる。代入は
<- または -> で行なう。
x <- 5 (xに5を代入) x -> y (yにxを代入)
式は入力と同時に評価される。変数への代入も行なえる。
1+2*3
[1] 7
出力の [1] は何項目かを表す番号。ベクトルで有用。
ベクトルは c() 関数で生成する。
c(1,2,3,4,5)
[1] 1 2 3 4 5
scan() 関数を利用すると,
空白区切りでデータ入力できる。終端記号として空行を入れる。
scan() 1: 1 3 5 7 5: 9 6: 11 13 8: Read 7 items [1] 1 3 5 7 9 11 13
ベクトルどうしの四則演算は要素ごとに行なわれる。
a=5 b=3 a*b [1] 15 a=c(1,2,3,4,5) b=scan() 1: 10 9 8 7 6 6: Read 5 items a [1] 1 2 3 4 5 b [1] 10 9 8 7 6 a*b [1] 10 18 24 28 30
seq(),rep()
は大量データを生成できる。前者は連続数,後者は同じ値の繰り返しを
ベクトルとして生成する。
seq(1, 40) [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [26] 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 1:40 [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [26] 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
[26] は,その行の先頭が第26項であることを示している。
2整数をコロン区切りで書いても同じ働きをするが,seq()
の第3引数でステップ値を指定できる。
seq(1,40,2)
[1] 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
> rep(5,10) [1] 5 5 5 5 5 5 5 5 5 5 rep(1:5, 3) [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
行列はベクトルを2次元にして生成する。matrix()
関数で生成できる。必要な個数の揃った1次元ベクトルを,
行数,列数指定して行列に変換する。
1:12 [1] 1 2 3 4 5 6 7 8 9 10 11 12 matrix(1:12, 2, 6) (2行6列) [,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 3 5 7 9 11 [2,] 2 4 6 8 10 12
列数だけ指定するときは ncol=列数
と指定できる(行数だけは nrow=行数)。
matrix(1:12, ncol=2)
[,1] [,2]
[1,] 1 7
[2,] 2 8
[3,] 3 9
[4,] 4 10
[5,] 5 11
[6,] 6 12
行方向を先に詰める場合は byrow=T を指定する。
matrix(1:12, ncol=2, byrow=T)
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
[4,] 7 8
[5,] 9 10
[6,] 11 12
行列からの特定要素,特定行, 特定列の取り出しを行なう添字指定の例を以下に示す。
m <- matrix(1:12,2,6) m [,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 3 5 7 9 11 [2,] 2 4 6 8 10 12 m[2,3] (2行目3列目) [1] 6 m[1,] (1行目) [1] 1 3 5 7 9 11 m[,5] (5行目) [1] 9 10 m[,c(1,3,5)] (1,3,5行目) [,1] [,2] [,3] [1,] 1 5 9 [2,] 2 6 10 m[,-c(1,3,5)] (1,3,5行目以外) [,1] [,2] [,3] [1,] 3 7 11 [2,] 4 8 12
列や行を結合してさらに行列を作ることができ,
行の結合には rbind(),列結合には cbind()
を利用する。
rbind(1:5, 11:15) [,1] [,2] [,3] [,4] [,5] [1,] 1 2 3 4 5 [2,] 11 12 13 14 15 cbind(1:5, 11:15) [,1] [,2] [1,] 1 11 [2,] 2 12 [3,] 3 13 [4,] 4 14 [5,] 5 15
主な算術関数を以下に示す。
sqrt(x) | 二乗根 |
abs(x) | 絶対値 |
log10(x) | 常用対数 |
log(x) | 自然対数 |
round(x) | 四捨五入 |
ceiling(x) | 引数以上の最小整数 |
floor(x) | 引数以下の最大整数 |
trunc(x) | 小数切り捨て |
統計関数を以下に示す。
mean(x) | 平均 |
var(x) | 不偏分散 |
sd(x) | 不偏標準偏差 |
標本分散と標本標準偏差を求める場合には,それぞれ
不偏分散(var())と標準偏差(sd())の結果を利用する。
平均を
![]() とすると,
とすると,
不偏分散
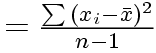
標本分散

なので,標本分散の値が必要なときは (n-1)倍してnで割る。 すなわち,
var(x)*(length(x)-1)/length(x)
が標本分散で,標本標準偏差はこれの2乗根,すなわち,
sqrt(var(x)*(length(x)-1)/length(x))
となる。頻繁に標本分散が必要になる場合は関数定義する。
関数定義は function を用い,
以下のようにする(svarは好きに決めた名前)。
svar <- function(x) {
var(x)*(length(x)-1)/length(x)
}
定義した関数は,他のオブジェクトと同じでR終了時にワークスペースの 保存を選べば次回も使える。
表形式のデータの行や列にラベル(名前)をつけた有機的な データ集合を保持するものがデータフレームである。
| 品名 | 単価 | 在庫数 |
|---|---|---|
| ピロリチョコ | 150 | 200 |
| キムチアイス | 130 | 4000 |
| コレラーメン | 298 | 300 |
ラベルと文字列は(日本語でもよい処理系もあるが) 英字でわかりやすいものを指定する。
c1 <- c("pirorichoco", "kimuchi ice", "koreramen") c2 <- c(150, 130, 298) c3 <- c(200, 4000, 300) d <- data.frame(item=c1, price=c2, stock=c3) d item price stock 1 pirorichoco 150 200 2 kimuchi ice 130 4000 3 koreramen 298 300
各列にそれぞれ "item", "price", "stock" とラベルのついたものが生成された。各列にはラベル経由でアクセスできる。 「データフレーム$ラベル」とすると, そのラベルのついた列のベクトルが得られる。
d$item [1] pirorichoco kimuchi ice koreramen d$price [1] 150 130 298
ベクトル添字にラベル名を文字列指定すると指定した列を 抽出したデータフレームが得られる。
d["item"] item 1 pirorichoco 2 kimuchi ice 3 koreramen d['stock'] (文字列は ' ' 括りでもよい) stock 1 200 2 4000 3 300
2列目と3列目のみ抽出する。
d[c(2,3)]
price stock
1 150 200
2 130 4000
3 298 300
「1列目以外」という指定でも2,3列目が取り出せる。
d[-1]
price stock
1 150 200
2 130 4000
3 298 300
特定の列「以外」は,添字に負数を指定する。
summary() 関数は要約統計量を出す。
summary(d[-1])
price stock
Min. :130.0 Min. : 200
1st Qu.:140.0 1st Qu.: 250
Median :150.0 Median : 300
Mean :192.7 Mean :1500
3rd Qu.:224.0 3rd Qu.:2150
Max. :298.0 Max. :4000
データフレームをファイルに読み書きできる。 空白区切りで二次元表形式データを書いた簡単なテキストファイルを 読み出してみる。以下のファイルを保存しておく。Rを起動したディレクトリ に配置する。
name height weight "YAMADA Taro" 175 62.1 c109300 168 58.8 c109301 172 56.3 "公益太郎" 180 74.2
1行目はヘッダで,これがデータフレームのラベルに利用される。 2行目以降が実際のデータで,第1列は氏名(name)を表す文字列で 敢えて変則的に入れてある。ダブルクォートで括ったものが1つの文字列値として 処理されることに注目せよ。
m <- read.table("w-head.txt", header=T) m (文字化けする処理系) name height weight 1 YAMADA Taro 175 62.1 2 c109300 168 58.8 3 c109301 172 56.3 4 \270\370\261\327\302\300\317\272 180 74.2 m (文字化けしない処理系) name height weight 1 YAMADA Taro 175 62.1 2 c109300 168 58.8 3 c109301 172 56.3 4 公益太郎 180 74.2 (nameは統計処理に不要なので1列目以外を抽出する) m[-1] height weight 1 175 62.1 2 168 58.8 3 172 56.3 4 180 74.2
データフレームを書き出すには write.table()
を使う。第1引数にオブジェクト,第2引数にファイル名を指定する。
write.table(m, "output.txt")
(output.txtに書き出される)
ファイル名を空にすると標準出力に書き出される。
write.table(m, "")
"name" "height" "weight"
"1" "YAMADA Taro" 175 62.1
"2" "c109300" 168 58.8
"3" "c109301" 172 56.3
"4" "公益太郎" 180 74.2
sep="区切り文字列"
でCSV出力にした例。
write.table(m, "", sep=",")
"name","height","weight"
"1","YAMADA Taro",175,62.1
"2","c109300",168,58.8
"3","c109301",172,56.3
"4","公益太郎",180,74.2
row.names=F
とすると行番号をつけない出力が得られる。
write.table(h, "", row.names=F, sep=",")
"name","height","weight"
"YAMADA Taro",175,62.1
"c109300",168,58.8
"c109301",172,56.3
"公益太郎",180,74.2
ファイル名を "clipboard"
にするとシステムのカットバッファとのやりとりになる。
Unixではカットバッファの読み取りのみできる。
たとえば,Calcの表の特定部分を領域選択したら
read.table("clipboard", sep="\t")
(あるいは)
scan("clipboard", sep="\t")
でデータの移行ができることになる。前者はデータフレームが得られ, 後者はベクトルが得られる。
次の標本の各種統計量を求めよ。
| Samp01 | 9 | 7 | 8 | 6 | 4 | 6 | 6 | 5 | 4 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|
| Samp02 | 5 | 9 | 5 | 8 | 8 | 5 | 10 | 9 | 4 | 8 |
| Samp03 | 3 | 6 | 5 | 8 | 7 | 5 | 2 | 5 | 6 | 6 |
| Samp04 | 5 | 3 | 7 | 2 | 8 | 3 | 3 | 5 | 3 | 5 |
| Samp05 | 6 | 7 | 7 | 7 | 4 | 8 | 3 | 3 | 7 | 7 |
| Samp06 | 5 | 5 | 5 | 9 | 6 | 6 | 7 | 5 | 6 | 1 |
| Samp07 | 6 | 7 | 6 | 5 | 5 | 6 | 6 | 4 | 5 | 8 |
| Samp08 | 5 | 3 | 6 | 6 | 4 | 2 | 6 | 4 | 7 | 5 |
| Samp09 | 2 | 4 | 4 | 4 | 6 | 7 | 10 | 4 | 7 | 7 |
| Samp10 | 5 | 5 | 4 | 6 | 6 | 4 | 4 | 6 | 1 | 6 |
Samp01の平均,分散,標準偏差を求めよ。
10個の数の集合はベクトルで入力する。 3つの方法を示す。
c() でベクトル生成する。
s01 <- c(9,7,8,6,4,6,6,5,4,5)
scan() を起動し,手入力する。
s01 <- scan()
9 7 8 6 4 6 6 5 4 5
ブラウザやCalcから10個のデータ領域を選択しておき,
scan() でカットバッファを読み取る。
データ部分を選択してから以下の操作をする。
s01 <- scan("clipboard", sep="\t")
ブラウザやCalcの表は領域選択するとカラム区切りに Tab文字を自動設定する。
以上のいずれかで s01 に Samp01
のデータを得たら,各統計量を計算する。
mean(s01) [1] 6 var(s01) [1] 2.666667 sd(s01) [1] 1.632993
Samp02の平均,分散,標準偏差を求めよ。
各自,Samp01と同様の手順で求めよ。
表1の10個の標本それぞれについて, 平均,分散,標準偏差を求めよ。
複数の標本がある場合はデータフレームに入れて処理するとよい。 まず,表1のデータ部分を領域選択して clipboard にコピーし, read.table で読み取る。
tmp <- read.table("clipboard") tmp V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 1 Samp01 9 7 8 6 4 6 6 5 4 5 2 Samp02 5 9 5 8 8 5 10 9 4 8 (中略) 10 Samp10 5 5 4 6 6 4 4 6 1 6
データ部分(V2〜V11)を抽出し, さらに転置する(行と列を入れ換える)。
tmp2 <- t(tmp[,-1]) tmp2 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] V2 9 5 3 5 6 5 6 5 2 5 V3 7 9 6 3 7 5 7 3 4 5 V4 8 5 5 7 7 5 6 6 4 4 (中略) V11 5 8 6 5 7 1 8 5 7 6
これをデータフレームに変換し,列の名前を付ける。 列の名前は tmp 変数の1列目を利用する。
sip1 <- data.frame(tmp2) names(sip1) <- tmp[,1] sip1 > tmp3 Samp01 Samp02 Samp03 Samp04 Samp05 Samp06 Samp07 Samp08 Samp09 Samp10 V2 9 5 3 5 6 5 6 5 2 5 V3 7 9 6 3 7 5 7 3 4 5 V4 8 5 5 7 7 5 6 6 4 4 V5 6 8 8 2 7 9 5 6 4 6 V6 4 8 7 8 4 6 5 4 6 6 V7 6 5 5 3 8 6 6 2 7 4 V8 6 10 2 3 3 7 6 6 10 4 V9 5 9 5 5 3 5 4 4 4 6 V10 4 4 6 3 7 6 5 7 7 1 V11 5 8 6 5 7 1 8 5 7 6
なお,転置する作業までを表計算ソフト上で行なってもよい。 データフレームに入れば,平均,分散,標準偏差も分かりやすく得られる。
(平均) mean(sip1) Samp01 Samp02 Samp03 Samp04 Samp05 Samp06 Samp07 Samp08 Samp09 Samp10 6.0 7.1 5.3 4.4 5.9 5.5 5.8 4.8 5.5 4.7 (分散) diag(var(sip1)) Samp01 Samp02 Samp03 Samp04 Samp05 Samp06 Samp07 Samp08 2.666667 4.544444 3.122222 3.822222 3.433333 4.055556 1.288889 2.400000 Samp09 Samp10 5.388889 2.455556 (標準偏差) sd(sip1) Samp01 Samp02 Samp03 Samp04 Samp05 Samp06 Samp07 Samp08 1.632993 2.131770 1.766981 1.955050 1.852926 2.013841 1.135292 1.549193 Samp09 Samp10 2.321398 1.567021
※問題:
diag() は何をする関数か?
また,diag() に渡さずに var(sip1)
した結果はどうなるか?
以下の設問をRで解く具体的な方法と解答をレポートにまとめ
sip-ii-03@e.koeki-u.ac.jp 宛に提出せよ(金曜締切)。
次の各標本の平均,標準偏差を求めよ。
read.table() 関数を利用してデータファイル
censor.txt
をデータフレームに読み取り,Depth,D-Range,ISOの3種の数値項目の
平均,標準偏差を求めよ。
1000人分の身長体重を収めたCSVファイル
hw1000.csv
をデータフレームに読み取り,身長,体重の平均,標準偏差を求めよ。
レポートは
の形式とする。
1種類の変量の標本はベクトルで処理してもよい。
2変量以上の標本はデータフレームで処理する。
手入力あるいは領域選択可能な程度の量のものは
表計算ソフトのデータを領域コピーし
read.table("clipboard")
で読み取る。
巨大なデータはCSVファイルなどに保存し
read.table("ファイル名")
で読み取る。1行目に英数字のラベルがあるものは
read.table("ファイル名", header=T)
で読み取る。