CSVとハッシュ
ヘッダ付きCSV
2科目分の試験の得点を記した score2.csv を考える。
山田太郎,50,70
中町太郎,90,80
飯森花子,91,60
鶴岡一人,60,45
酒田三吉,52,82
三川一二三,12,98
このようなデータを渡されても50と70が何を意味しているのか不明なので、
通常は見出しとなるヘッダ行をつけて以下のように書く。
score2h.csv
氏名,数学,英語
山田太郎,50,70
中町太郎,90,80
飯森花子,91,60
鶴岡一人,60,45
酒田三吉,52,82
三川一二三,12,98
表計算プログラムでみると以下のように見えるはずである。
| A | B | C |
|---|
| 1 | 氏名 | 数学 | 英語 |
|---|
| 2 | 山田太郎 | 50 | 70 |
|---|
| 3 | 中町太郎 | 90 | 80 |
|---|
| 4 | 飯森花子 | 91 | 60 |
|---|
| 5 | 鶴岡一人 | 60 | 45 |
|---|
| 6 | 酒田三吉 | 52 | 82 |
|---|
| 7 | 三川一二三 | 12 | 98 |
|---|
1行目が見出しとなるヘッダ行を持つCSVファイルは CSV.read
を用い
CSV.read(CSVファイル名, headers: true)
とすると、ヘッダ構造を持った値になる。具体的には以下のように利用する。
seiseki = CSV.read("score2h.csv", headers: true)
こうすると、seiseki 変数は、行ごとの値を
ヘッダ行の項目名で取り出せる値を集めた配列になる。
score2h.csvを保存してから、
以下のようにirbで読み取る実験をしよう。
irb -rcsv # CSVライブラリを最初からrequireする
seiseki = CSV.read("score2h.csv", headers: true)
seiseki[0] # 先頭要素を取り出す
=> #<CSV::Row "氏名":"山田太郎" "数学":"50" "英語":"70">
seiseki[0]["数学"] # 先頭要素の "数学" 値を取り出す
=> "50"
このように、各レコード(行)のうち、項目に対応する値を「添字」の
形でアクセスできる。単純に全部のCSVデータを出力する
プログラム例を示す。
score-csvheader.rb
#!/usr/koeki/bin/ruby
# -*- coding: utf-8 -*-
require 'csv'
seiseki = CSV.read(ARGV[0], headers: true)
seiseki.each do |row| # レコードごとに値をrowに入れて繰り返す
name = row["氏名"] # 添字 "氏名" で氏名欄の値
math = row["数学"].to_i # 添字 "数学" で数学欄の値 .to_iで整数化
eng = row["英語"].to_i # 添字 "英語" で英語欄の値 .to_iで整数化
printf("%sさんの数学は%d点、英語は%d点です。\n", name, math, eng)
end
実行例を示す。
./score-csvheader.rb score2h.csv
山田太郎さんの数学は50点、英語は70点です。
中町太郎さんの数学は90点、英語は80点です。
飯森花子さんの数学は91点、英語は60点です。
鶴岡一人さんの数学は60点、英語は45点です。
酒田三吉さんの数学は52点、英語は82点です。
三川一二三さんの数学は12点、英語は98点です。
列の取り出し
headers:trueで読んだ値からは、
特定の列のみ取り出せる。
seiseki = CSV.read("score2h.csv", headers: true)
で代入されている前提でseiseki["数学"]は、
数学のみを「縦に」集めた配列、つまり
| A | B | C |
|---|
| 1 | 氏名 | 数学 | 英語 |
|---|
| 2 | 山田太郎 | 50 | 70 |
|---|
| 3 | 中町太郎 | 90 | 80 |
|---|
| 4 | 飯森花子 | 91 | 60 |
|---|
| 5 | 鶴岡一人 | 60 | 45 |
|---|
| 6 | 酒田三吉 | 52 | 82 |
|---|
| 7 | 三川一二三 | 12 | 98 |
|---|
のB列の値の部分を集めた配列
["50", "90", "91", "60", "52", "12"]
となる(文字列であることに注意)。同様に、
は、
["70", "80", "60", "45", "82", "98"]
となる。このことから、たとえば「数学の合計点」
を求めるには以下のようにすればよい。
sum = 0
seiseki["数学"].each do |pt|
sum += pt.to_f
end
ヘッダの取り出し
headers:trueで読んだ値から、ヘッダ(見出し項目)一覧を
取り出せる。
seiseki = CSV.read("score2h.csv", headers: true)
と代入されている場合、見出し行を集めた配列はheaders
にアクセスすることで得られる。
seiseki.header
["氏名", "数学", "英語"]
| A | B | C |
|---|
| 1 | 氏名 | 数学 | 英語 |
|---|
| 2 | 山田太郎 | 50 | 70 |
|---|
| 3 | 中町太郎 | 90 | 80 |
|---|
| : |
これを利用すると、見出し行付きのCSVファイルから自動的に見出しを読み取って
集計できる。キャラ一覧CSV
を読み取り、項目名で分類したものを出力してみる。
byheader.rb
#!/usr/koeki/bin/ruby
# -*- coding: utf-8 -*-
require 'csv'
csv = CSV.read(ARGV[0], headers:true)
for field in csv.headers # csv.headers.each do |field| でも同じ
printf("「%s」列の値一覧: %s\n", field, csv[field])
end
実行例:
./byheader.rb score2h.csv
「氏名」列の値一覧: ["山田太郎", "中町太郎", "飯森花子", "鶴岡一人", "酒田三吉", "三川一二三"]
「数学」列の値一覧: ["50", "90", "91", "60", "52", "12"]
「英語」列の値一覧: ["70", "80", "60", "45", "82", "98"]
問題
score-csvheader.rb を改良して、
数学の平均点、英語の平均点の両方を求めて出力するプログラム
avg-me.csv を作成せよ(答は何パターンもある)。
実行例:
./avg-me.rb score2h.csv
数学の平均点は59.2点です。
英語の平均点は72.5点です。
score2h.csv
の英語の右隣りの列に、見出し "国語" を追加して、6名の行の
右側にも国語の点数を(適当に)追加したCSVファイル
score3h.csv を作成せよ。
上で作成したscore3h.csvを読み取り、
誰がどの科目で何点を取ったかを出力するプログラム
score3h.rb を作成せよ。
score-csvheader.rbを見本にするとよい。
実行例を以下に示す。
./score3h.rb score3h.csv
山田太郎さんの数学は50点、英語は70点、国語は60点です。
中町太郎さんの数学は90点、英語は80点、国語は85点です。
(以下略)
上で作成したscore3h.rbとavg-me.rb
を参考にして、score3h.csvにある数学、英語、国語の
各平均点を計算して出力するプログラムavge-mej.rb
を作成せよ。実行例を以下に示す。
./avg-mej.rb score3h.csv
数学の平均点は59.2点です。
英語の平均点は72.5点です。
国語の平均点は61.8点です。
キャラクタ一覧にある
値を保持するCSVファイルを作成せよ。ファイル名は
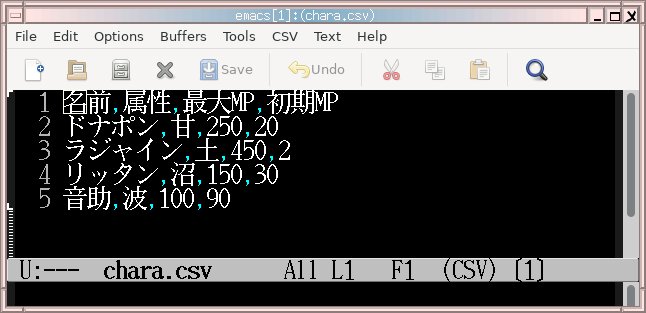
chara.csvで保存せよ。入力完了後の画面例を示す。
上で作成したchara.csvを読み込んで、
存在する「属性」値一覧を出力するプログラム
chara-attr.rbを作成せよ。
属性値を持つ配列はそのまま printf の %s で
出力してよい(以下実行例)。
./chara-attr.rb
属性一覧: ["甘", "土", "沼", "波"]
【課題7a】
自分が趣味としてよく覚えているものについて、見出し項目を
適切に整理した形でデータ化したCSVファイルを
mydata.csv のファイル名で作成せよ。
レコード(データ行数)は10件以上とし、
項目(列数)は5カラム以上とする。
【データの例】
ゲームのキャラデータ、スポーツ選手一覧、記録一覧、歴代○○、
花言葉など、地理的な数値一覧、……などなど
※注意※ 1行目は必ず項目名とし、2行目以降に実際のデータ
を書くこと。必ず csvcheck.rb
を保存し、
を実行し、エラーがないことを確認せよ。
【課題7b】
上で作成したCSVファイル mydata.csv
を読み込み、特定の項目、または特定のレコードのみを選んで出力するような
プログラム mydata.rb を作成せよ。
自分なりに便利な機能を考えて作り込むこと。
上記の問題で作成した chara.csv
を読んで選別するプログラムを作成した例を示す: →
キャラ選別作成プログラム
参考:CSVファイルの作り方
CSVファイルの作成は以下のいずれかで行うとよい。
- 表計算ソフト(Calcなど)で編集
- Emacs(のcsv-mode)で編集
※注意 標準的なExcelでは期待通りの
CSVファイルを作ることはできない(後述)。EmacsまたはLibreOffice/Calcで
作ることを推奨する。
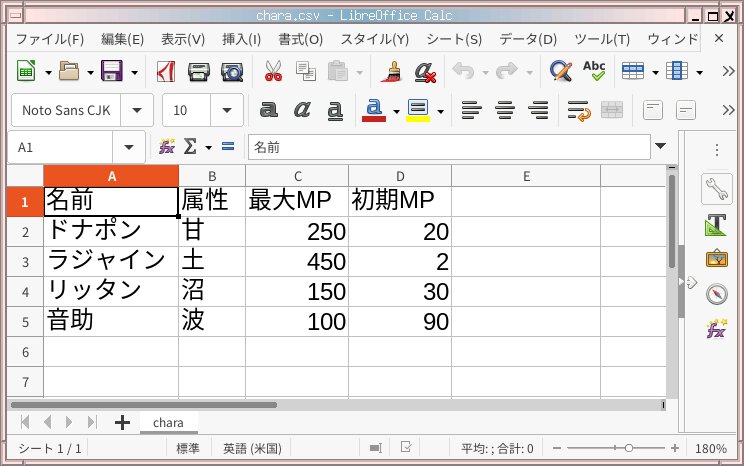
Calcの場合
LibreOffice/Calcを起動し、データを入力したら
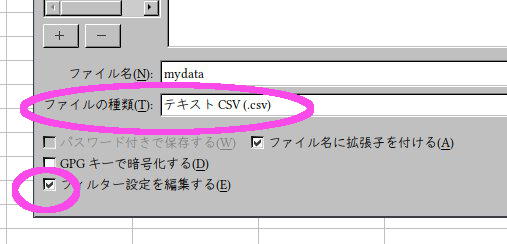
メニュー: ファイル → 名前をつけて保存
ファイル名入力右下保存種別の「ODF表計算ドキュメント」を
「テキストCSV(.csv)」に変え、「フィルター設定を編集する」に
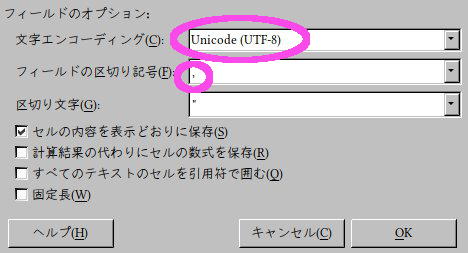
チェックしてからファイル名をつけて保存 →
文字エンコーディングは「UTF-8」、フィールドの区切り記号はカンマ
Emacsの場合
CSVファイルを開いたときに以下のようにモードラインに「(CSV)」と
出ていれば専用編集機能が使える。
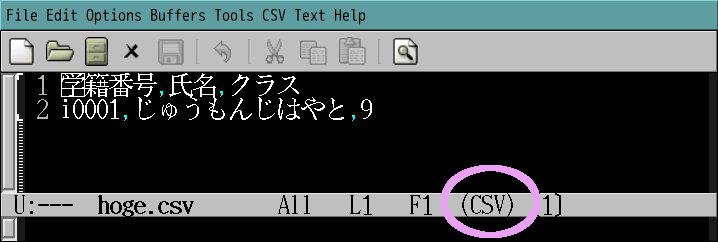
(ついていない場合は相談)
この状態で C-c C-a をタイプするとCSVのフィールドごとに
桁が揃って表示される。
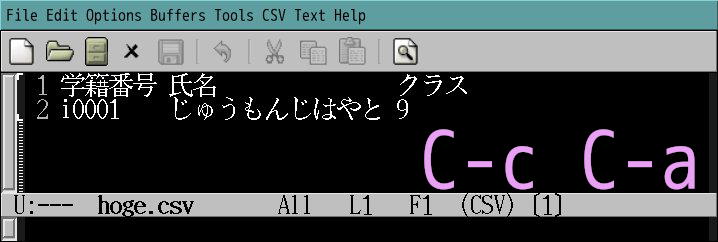
項目を1つ入れたら Tab キーを押すと次の項目に進む。
Excelの場合(煩雑)
我々が作成するCSV.readで正常に処理できるCSVファイルをExcelでは作れない。
理由は「Excel BOM CSV」で検索すること。根深い問題だと理解できればよい。
どうしても入力がExcelでしかできないなら、自宅PCなどで作成したものを
Emailやクラウドで学内環境に転送し、Calcで編集する。あるいは以下のように
KoekiDriveを介して作成する。
- KoekiDrive2にログイン
(ログイン名は大学アカウントのEmailアドレス)
- 上に並ぶアイコンから「ファイル」アプリに進む
- 保存したいフォルダを選び (+ New) ボタンで「新規スプレッドシート」
を開くか自宅PCで作成したExcelファイルをアップロードしすぐ編集する。
- データを入力し終わったら最上列メニュー「ファイル」を選び
「ダウンロード」→「CSVファイル(.csv)」を選ぶ
本日の目次へ