3つのテーブルの関係
これまで説明したテーブル設計とCSSの機構を組み合わせ、 動作するカタログ型データベースの実際の挙動と仕様を定義していく。
抽象的な設計ではイメージがつかみづらいので、 実際に取り扱うデータを具体的に定めて考察したい。 ここでは、以下のような情報提供画面を持つものの設計を考える。
いくつかの品物の、名前、写真(画像)、種別、説明文、参考情報、 を掲載するカタログデータベースを作成する。1品ごとの掲載ページは 以下のようなものとする。
ID item001 品名 つや姫 写真 商品
の
画像種別 穀物 説明 商品その1の説明短文(複数可) 参考情報 商品その1に関する
長めの文章(複数可)特産物カタログの画面例
このような形式のものを必要な品数だけ保持できるものを考える。
「Key-Valueストアのエミュレーション」で述べた。 3つ組テーブル設計を使ってこのカタログデータの格納を実装する。 3つ組テーブルとは具体的に以下のような3つのテーブルに分けることを指す。
上記3つのテーブルをそれぞれ cards、cards_s、cards_m とし、 実際のテーブルで表現すると以下のようになる。
3つ組テーブルの作成
-- 主キーテーブル
CREATE TABLE cards(id text PRIMARY KEY);
-- 単一値テーブル
CREATE TABLE cards_s (
id, key text, val, bin blob,
FOREIGN KEY(id) REFERENCES cards(id)
ON DELETE CASCADE ON UPDATE CASCADE,
UNIQUE(id, key)
);
-- 多値テーブル
CREATE TABLE cards_m(
id, key text, val, bin blob,
FOREIGN KEY(id) REFERENCES cards(id)
ON DELETE CASCADE ON UPDATE CASCADE,
UNIQUE(id, key, val)
);
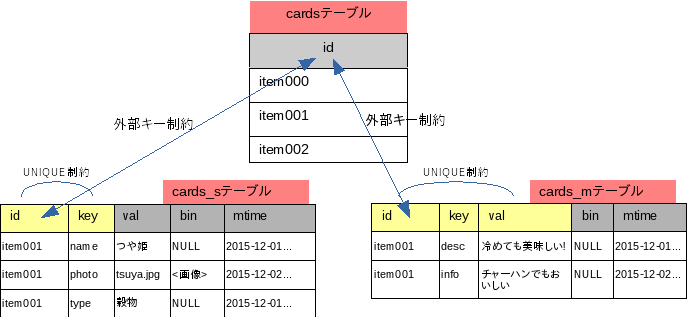
3つのテーブルの関係を図示する。
3つのテーブルの関係
図「特産物カタログの画面例」で示したようなカタログの作成を考える。 データの格納先テーブルはリスト「3つ組テーブルの作成」で示したもので問題ないが、 実際にデータの入出力を行なうためには、どの属性をどのテーブルに保存するかを 自動的に判断する必要がある。 今回の例であれば以下のような属性情報を判断の基にする。
| 属性(項目名) | カラム名 | 値の種別 | カラムの種別 | その他の付加情報 |
|---|---|---|---|---|
| ID | id | 主キー | 1行テキスト | |
| 品名 | name | 単一値 | 1行テキスト | |
| 写真 | photo | 単一値 | 画像 | |
| 種別 | type | 単一値 | 選択 | 野菜 穀物 果物、のどれか |
| 説明 | desc | 多値 | 1行テキスト | |
| 参考情報 | info | 多値 | 複数行テキスト | 40桁3行の入力窓 |
このような属性情報もさらにデータとして格納し、 スクリプトで把握させておく必要がある。 簡略化のため上記の表の分類中の言葉を以下のように置き換える。
| 置き換え前 | 置き換え後 | 備考 | |
|---|---|---|---|
| 「主キー」 | → | P | (P)rimary Key |
| 「単一値」 | → | S | (S)ingle |
| 「多値」 | → | M | (M)ultiple |
| 「1行テキスト」 | → | text | |
| 「複数行テキスト」 | → | textarea | HTMLのフォームでtextareaを用いるので |
| 「画像」 | → | image | |
| 「選択」 | → | select | HTMLのフォームでselectを用いるので |
| 「40桁3行の入力窓」 | → | cols=40 rows=3 | textareaに指定する値をそのまま書く |
これをコロン区切りでテキストファイル化したものを以下に示す。
# 項目名:属性:属性種別:値種別:値オプション
ID:id:P:text
品名:name:S:text
写真:photo:S:image
種別:type:S:select:野菜 穀物 果物
説明:desc:M:text
参考情報:info:M:textarea:cols=40 rows=3
この定義ファイルを読み込んで、属性情報として格納するテーブルを設計する。
| カラム | 型 | 意味 |
|---|---|---|
| attrname | TEXT | 項目名 |
| attr | TEXT | 属性になり得る値 |
| attrmode | TEXT | その属性の種別 |
| vtype | TEXT | 値の種別 |
| option | TEXT | HTMLフォームで利用するオプションなど |
ここまでに必要と判明したテーブル設計と初期値の格納を行なうものを作成する。 必要なテーブルを CREATE TABLE し、上掲 cards.def ファイルを読み込みつつテーブルに格納していくものを記述すると以下のようになる。
カラム属性情報テーブル初期化の流れ
cat<<EOF | sqlite3 データベースファイル
DROP TABLE IF EXISTS _columns;
CREATE TABLE _columns(
attrname text,
attr text PRIMARY KEY,
attrmode text,
vtype text,
option text
);
EOF
grep -v '^#' cards.def |
while IFS=: read aname attr atmode vtype opt; do
cat<<-EOF
REPLACE INTO _columns VALUES(
'$aname', '$attr', '$atmode', '$vtype', '$opt'
);
EOF
done | sqlite3 データベースファイル
cat から始まる前半部は、_columns テーブルが既にあれば破棄したうえで、新規に _columns テーブルを作成している。 grep から始まる後半部では、cards.def ファイルからコメント行以外を順次読み取る。 単語区切りをコロン(:)にすることで各フィールドがそれぞれシェル変数 aname、attr、atmode、vtype、opt に代入されて処理が繰り返される。 各々の行の値を用いて「REPLACE INTO ....」の問い合わせ文が実行される。これにより、例示した cards.def を読み込んだあとの _columns テーブルは以下の値を持つ(表形式で示す)。
| attrname | attr | attrmode | vtype | option |
|---|---|---|---|---|
| ID | id | P | text | |
| 品名 | name | S | text | |
| 写真 | photo | S | image | |
| 種別 | type | S | select | 野菜 穀物 果物 |
| 説明 | desc | M | text | |
| 参考情報 | info | M | textarea | cols=40 rows=3 |
1つの品目に関連する値は3つのテーブルに分割して格納する。 HTMLのフォーム入力から送り込まれた値を、複数のテーブルに適切に振り分けて 入れる手順を考える。
図「特産物カタログの画面例」で示したような値が 以下のような画面で入力された場合を考える。
id item001 品名 つや姫
写真 種別 説明 庄内産のつや姫です。
参考情報 デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。
カタログデータの入力画面例
入力はidを除く5つで、上から順に表「特産物カタログでの _columns テーブルの内訳」の attr 列に記載された input 名を付けるべきだが、値を受け取ったシェルスクリプトでの判断負担を軽減するため あらかじめ input 名に、 データベース中のどこに格納すべきかの情報を埋め込んでおく。 たとえば、「品名」は単一値なので格納テーブルは cards_s であり、 「説明」は多値なので格納テーブルは cards_m であるから、たとえば 「品名」の input 名を name.s、「説明」の input 名を desc.m のようにする方針を考える。
上記画面例からさらに多値属性に値を入れて以下のように複数の値が入ったとする。
多値入力例 説明 庄内産のつや姫です。 説明 今年度産 5kg 包装です。
これはたとえば cards_m テーブルに以下のような状態で格納される(rowid は仮のものを想定)。
| rowid | id | key | val | bin |
|---|---|---|---|---|
| 5 | tsuyahime | desc | 庄内産のつや姫です。 | NULL |
| 9 | tsuyahime | desc | 今年度産 5kg 包装です。 | NULL |
これらの値を修正するための入力フォームを出す場合、2つの input 要素が必要になるが、 それぞれがどちらの行のものなのか区別できるようにしなければならない。 そこで以下のような方針で input 要素を生成する。
上記の2つのレコードでの具体例で示すと以下のようになる。
説明1: <input name="desc.1.m" value="庄内産のつや姫です。">
<input type="hidden" name="rowid.desc.1.m" value="5">
説明2: <input name="desc.2.m" value="今年度産 5kg 包装です。">
<input type="hidden" name="rowid.desc.2.m" value="9">
上記のようなフォーム文からの入力値を cgilib2 の storeparam() 関数で受け取ると、各々の値は cgipars テーブルに以下のように格納される(他のinputの値も交ぜてある)。
| tag | name | val | filename |
|---|---|---|---|
| 1449932122.21134 | photo.1.s | 画像バイナリデータ | tsuyahime.jpg |
| 1449932122.21134 | rowid.photo.1.s | 4 | NULL |
| 1449932122.21134 | desc.1.m | 庄内産のつや姫です!! | NULL |
| 1449932122.21134 | rowid.desc.1.m | 5 | NULL |
| 1449932122.21134 | desc.2.m | 新米 5kg 包装です。 | NULL |
| 1449932122.21134 | rowid.desc.2.m | 9 | NULL |
参考までに上記の状態の cgipars を作成する実行例を示す。
tag='1449932122.21134'
sqlite3 データベースファイル<<EOF
CREATE TABLE IF NOT EXISTS tags(id text PRIMARY KEY, expire TEXT);
CREATE TABLE IF NOT EXISTS cgipars(
tag, name text, val text, filename,
FOREIGN KEY(tag) REFERENCES tags(id) ON DELETE CASCADE
);
INSERT INTO tags VALUES('$tag', datetime('now', '+2 hours', 'localtime'));
INSERT INTO cgipars VALUES('$tag', 'photo.1.s', 'aaaaaa', 'tsuyahime.jpg');
INSERT INTO cgipars VALUES('$tag', 'rowid.photo.1.s', 4, NULL);
INSERT INTO cgipars VALUES('$tag', 'desc.1.m', '庄内産のつや姫です', NULL);
INSERT INTO cgipars VALUES('$tag', 'rowid.desc.1.m', 5, NULL);
INSERT INTO cgipars VALUES('$tag', 'desc.2.m', '新米 5kg 包装です。', NULL);
INSERT INTO cgipars VALUES('$tag', 'rowid.desc.2.m', 9, NULL);
EOF
これらの値から desc に関するものを取り出し、以下のような REPLACE 文に相当するものとしたい。
REPLACE INTO cards_m(rowid, id, key, val, bin) VALUES(
5, 'item001', 'desc', '庄内産のつや姫です。', NULL
);
REPLACE INTO cards_m(rowid, id, key, val, bin) VALUES(
9, 'item001', 'desc', '今年度産 5kg 包装です。', NULL
);
VALUES(…) に相当する部分を、cgipars からの SELECT で得ればよい。方法は何通りもあるが以下のような SQL 文で所望の動作をする。
cgiparsからcards_mへの値コピー(1)
WITH pars AS (SELECT * FROM cgipars WHERE tag='1449932122.21134')
REPLACE INTO cards_m
SELECT
(SELECT val FROM pars WHERE name='rowid.'||c.name) rid,
substr(name, 1, instr(name, '.')-1) attrname,
val, filename
FROM pars c
WHERE name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
この文に至るまでの考え方が重要なので、順を追って示す。
cgiparsテーブルの値から、name が 属性名.通し番号.m にマッチするもののみ抜き出す。
.header on -- 以後出力例の1行目はカラムヘッダ
SELECT name, val, filename
FROM cgipars
WHERE tag='1449932122.21134'
AND name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
name|val|filename
desc.1.m|庄内産のつや姫です!!|NULL
desc.2.m|新米 5kg 包装です。|NULL
name のパターンを '%.%.m' とすると、'rowid.desc.1.m' などにもマッチするので、それらを除外するために NOT LIKE 'rowid.%' という条件を追加している。
上記の出力に加えて、desc.1.m および desc.2.m の値を cards_m に格納するときの rowid を得たい。つまり desc.1.m なら 5、desc.2.m なら 9 である。name カラムの出力("desc.1.m" と "desc.2.m")文字列の前に "rowid." を前置したものが name となる行の val を取得すると、それは cards_m テーブルに格納するときの rowid となる。最初の問い合わせに副問い合わせを加える。
SELECT
(SELECT val FROM cgipars WHERE tag='1449932122.21134'
AND name='rowid.'||c.name) rid,
name, val, filename
FROM cgipars c
WHERE tag='1449932122.21134'
AND name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
rid|name|val|filename
5|desc.1.m|庄内産のつや姫です!!|NULL
9|desc.2.m|新米 5kg 包装です。|NULL
主問い合わせ(外側のSELECT)の cgipars テーブルを別名 c とした。 副問い合わせ(内側のSELECT)での 「name='rowid.'||c.name」の条件は、その時点で抽出された行の name カラムの値が c.name で得られる。たとえば、外側の SELECT 文で "desc.1.m" を出力対象としているときには、c.name='desc.1.m' となるので、 'rowid.'||c.name の値は 'rowid.desc.1.m' になる。 したがって、この瞬間の副問い合わせの条件は
WHERE tag='1449932122.21134' AND name='rowid.desc.1.m'と等価になり、副問い合わせの結果は 5 となる。 なお、副問い合わせ全体の別名を rowid とした。これで desc.1.m は cards_m の rowid=5 の行と関連づけられる。
name カラムの出力 desc.1.m などから 通し番号.m の部分を削除する。SQLite3 の substr 関数で部分文字列を得る。
substr(文字列, 開始位置, 文字数)
の構文で、先頭の文字位置は1である。 削除すべき位置を得るために instr 関数を使う。
instr(文字列, 検索文字列)
文字列 の中から、検索文字列 を探し、見付かった文字位置を返す。name の値が 'desc.1.m' だとすると、ピリオド以降を切り取った結果は以下で得られる。
substr(name, 1, instr(name, '.')-1)
SELECT
(SELECT val FROM cgipars WHERE tag='1449932122.21134'
AND name='rowid.'||c.name) rid,
substr(name, 1, instr(name, '.')-1) attrname,
val, filename
FROM cgipars c
WHERE tag='1449932122.21134'
AND name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
rid|attrname|val|filename
5|desc|庄内産のつや姫です!!|NULL
9|desc|新米 5kg 包装です。|NULL
必須ではないが、cgiparsから現在のセッション(1449932122.21134)のもののみ 抜き出す一時ビューを WITH 句で作り、問い合わせの冗長感をなくす。
WITH pars AS (SELECT * FROM cgipars WHERE tag='1449932122.21134')
SELECT
(SELECT val FROM pars WHERE name='rowid.'||c.name) rid,
substr(name, 1, instr(name, '.')-1) attrname,
val, filename
FROM pars c
WHERE name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
リスト「cgiparsからcards_mへの値コピー(1)」 は入力値がテキストの場合のみうまく機能する。表「修正値が送信された直後の cgipars テーブルの値(抜粋)」にあるような 画像バイナリデータ は cards_m.val ではなく、 cards_m.bin にコピーすべきである(下図参照)。
テキストとバイナリでのカラム切り替え
| コピー元 | cards_mでのカラム | |
|---|---|---|
| cgipars.val | → | val |
| NULL | → | bin |
| コピー元 | cards_mでのカラム | |
|---|---|---|
| cgipars.filename | → | val |
| cgipars.val | → | bin |
cards_m テーブルへのレコード挿入は以下のような 5つの値の並びで問い合わせで行なうものであった。
REPLACE INTO cards_m(rowid, id, key, val, bin) VALUES(.....);
バイナリデータの挿入も考慮するなら VALUES に相当する並びは以下の順にする。
テキスト値かバイナリ値かの判定は key となる値を _columns.vtype が image かどうか調べればよい。 これを問い合わせ文にまとめると以下のようになる。
cgiparsからcards_mへの値コピー(2)
WITH pars AS (SELECT * FROM cgipars WHERE tag='1449932122.21134')
SELECT
(SELECT val FROM pars WHERE name='rowid.'||c.name) rid,
substr(name, 1, instr(name, '.')-1) attrname,
CASE (SELECT vtype FROM _columns WHERE name LIKE attr||'.%')
WHEN 'image' THEN filename
ELSE val
END val,
CASE (SELECT vtype FROM _columns WHERE name LIKE attr||'.%')
WHEN 'image' THEN val
ELSE NULL
END bin
FROM pars c
WHERE name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
テキスト値かバイナリ値かの切り替えを CASE 文で行なった。 CASE で判定している式:
SELECT vtype FROM _columns WHERE name LIKE attr||'.%'
は、そのときの name カラムの値が _columns テーブルの attr の値に '.%' を付けたパターン(%はSQLのワイルドカード)とマッチする場合の vtype、 つまり値の種別を返す。たとえば name が 'desc.1.m' であれば、 これが attr||'.%' というパターンにマッチするときの attr は 'desc' であるから、vtype='text' である。さらにたとえば name が 'photo.1.s' の場合は attr||'.%' にマッチする attr は photo なので、そのとき vtype='image' である。
WHEN 'image' THEN filename
ELSE val
によって、式の値が 'image' の場合には filename カラムの値が、 それ以外のときは val カラムの値が返る。同様の処理が2つ目の CASE 文で行なわれ、結果として表「テキストとバイナリでのカラム切り替え」を実現しつつ、 cgipars にあるフォーム送信値を cards_m にコピーする SQL 文は以下のようになる。
WITH pars AS (SELECT * FROM cgipars WHERE tag='1449932122.21134')
REPLACE INTO cards_m
SELECT
(SELECT val FROM pars WHERE name='rowid.'||c.name) rid,
substr(name, 1, instr(name, '.')-1) attrname,
CASE (SELECT vtype FROM _columns WHERE name LIKE attr||'.%')
WHEN 'image' THEN filename
ELSE val
END val,
CASE (SELECT vtype FROM _columns WHERE name LIKE attr||'.%')
WHEN 'image' THEN val
ELSE NULL
END bin
FROM pars c
WHERE name LIKE '%.%.m' AND name NOT LIKE 'rowid.%';
cgilib2 ライブラリでは、セッションIDは $_tag に保存されているので上記の WITH 句は、シェルスクリプト中では以下のように記述すべきである。
WITH pars AS (SELECT * FROM cgipars WHERE tag='$_tag')
上記の SQL 文を、cards_s(単一値用) と cards_m(多値用) 両方のテーブルに適用させる。 これはシェルスクリプトで以下のように繰り返した SQL 文の生成結果を問い合わせ用のシェル関数に渡すだけでよいだろう。
_tb=cards
for t in s m; do
tb=${_tb}_$t # cards_s または cards_m になる
cat<<-EOF
WITH pars AS (SELECT * FROM cgipars WHERE tag='$_tag')
REPLACE INTO $tb # $tがsならcards_s、$tがmならcards_m
:
中略
:
WHERE name LIKE '%.%.$t' AND name NOT LIKE 'rowid.%';
EOF
done | query # queryは問い合わせを行なうシェル関数
1つのレコード中のある属性値を削除する場合を考えよう。 上記の例のとおり、多値テーブルに id='item001' に付随する以下の値が登録されているとする。
| rowid | id | key | val | bin |
|---|---|---|---|---|
| 5 | tsuyahime | desc | 庄内産のつや姫です!! | NULL |
| 9 | tsuyahime | desc | 新米 5kg 包装です。 | NULL |
ここから rowid=9 のものを削除する指定が利用者から発せられたとする。 今回想定しているユーザインタフェースでは、以下のような画面で削除確認が出る。
説明2 ○温存 ○変更 ○新規 削除 本当に消しますか: □はい
新米 5kg 包装です。
このときに出力されている input 要素のうち、 削除操作のときに参照すべきものを抜粋する。
<input name="action.desc.2.m" type="radio" value="rm"> <!-- 削除ボタン -->
<input name="rowid.desc.2.m" type="hidden" value="9"> <!-- rowid -->
<input name="cfm.desc.2.m" type="checkbox" value="yes">はい <!-- 確認のチェックボックス -->
<input name="desc.2.m" type="text" value="新米 5kg 包装です。">
これらのフォームで「削除」と「はい」のボタンが両方とも押されたとすると、 cgipars には以下のように値が設定される。
| tag | name | val | filename |
|---|---|---|---|
| 1450049253.4499 | action.desc.2.m | rm | NULL |
| 1450049253.4499 | cfm.desc.2.m | yes | NULL |
| 1450049253.4499 | desc.2.m | 新米 5kg 包装です。 | NULL |
| 1450049253.4499 | rowid.desc.2.m | 17 | NULL |
以下のアルゴリズムにより、cards_m から削除すべき rowid を求める(||はSQLの文字列結合演算子)。
順に SQL 文に直していくと、1 は WITH 句で以下の絞り込みを行なう。
WITH pars AS (SELECT * FROM cgipars WHERE tag='現セッション値')
続いて手順3で、WITHによる pars を利用して以下のようにする。
WITH pars AS (SELECT * FROM cgipars WHERE tag='現セッション値')
SELECT * FROM pars p
WHERE 'rm' = (SELECT val FROM pars WHERE name='action.'||p.name)
AND 'yes' = (SELECT val FROM pars WHERE name='cfm.'||p.name)
AND name LIKE '%.m';
これにより、上記の表に示した例であれば 'desc.2.m' の行が選択される。 欲しい値はそこではなく、name='rowid.desc.2.m' の場合の val であるから、「SELECT *」の部分を以下のように修正する。
WITH pars AS (SELECT * FROM cgipars WHERE tag='現セッション値')
SELECT (SELECT val FROM pars
WHERE name='rowid.'||p.name)) rid
FROM pars p
WHERE 'rm' = (SELECT val FROM pars WHERE name='action.'||p.name)
AND 'yes' = (SELECT val FROM pars WHERE name='cfm.'||p.name)
AND name LIKE '%.m';
これで削除すべき rowid が得られるため、上記の式を DELETE FROM に渡す。消すべき rowid は1つとは限らないので IN で判定する。
DELETE FROM cards_m WHERE rowid IN (
WITH pars AS (SELECT * FROM cgipars WHERE tag='現セッション値')
SELECT (SELECT val FROM pars
WHERE name='rowid.'||p.name)) rid
FROM pars p
WHERE 'rm' = (SELECT val FROM pars WHERE name='action.'||p.name)
AND 'yes' = (SELECT val FROM pars WHERE name='cfm.'||p.name)
AND name LIKE '%.m');
値の更新のときと同様、 2つのテーブルに対してシェルスクリプトでループを形成すればよい。 更新時と同様セッションIDはシェル変数 _tag に入っているものとする。
_tb=cards
for t in s m; do
tb=${_tb}_$t
cat<<-EOF
DELETE FROM $tb WHERE rowid IN (
WITH pars AS (SELECT * FROM cgipars WHERE tag='$_tag')
SELECT (SELECT val FROM pars
WHERE name='rowid.'||p.name)) rid
FROM pars p
WHERE 'rm' = (SELECT val FROM pars WHERE name='action.'||p.name)
AND 'yes' = (SELECT val FROM pars WHERE name='cfm.'||p.name)
AND name LIKE '%.$t');
EOF
done | query
「項目名で整列した出力」で示したような表形式の出力を、 値の出力と同時に、項目値の編集や削除のインタフェース提示もできるようにしたい。
たとえば特産物(id='item001')に関する値が以下のようにテーブル格納されているとする。
| id | key | val | bin |
|---|---|---|---|
| item001 | name | つや姫 | NULL |
| item001 | photo | tsuyahime.jpg | 画像バイナリデータ |
| item001 | type | 穀物 | NULL |
| id | key | val | bin |
|---|---|---|---|
| item001 | desc | 庄内産のつや姫です。 | NULL |
| item001 | desc | 新米 5kg 包装です。 | NULL |
| item001 | info | デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。 | NULL |
これを、所定の key 順に表形式で出力する。key 一覧は _columns テーブルに格納されている。画像バイナリデータはのちに考えるとして、 key と val のすべての対応表を出力するには、以下のように JOIN を組み立てればよい。
属性名リスト _columns a rowid attrname attr 1 ID id 2 品名 name 3 写真 photo 4 種別 type 5 説明 desc 6 参考情報 info ×
id='item001' で得られる和集合 b key val name つや姫 photo tsuyahime.jpg type 穀物 desc 庄内産のつや姫です。 desc 新米 5kg 包装です。 info デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。 属性一覧と「単一値・多値テーブルのUNION」のJOIN
表形式出力を得るSQL文(1)
SELECT a.attrname, a.attr, b.val
FROM (SELECT * FROM _columns) a
LEFT JOIN
(SELECT * FROM cards_s WHERE id='item001'
UNION ALL
SELECT * FROM cards_m WHERE id='item001') b
ON a.attr=b.key
ORDER by a.rowid;
この問い合わせで得られる結果を表形式で表したものを示す。
| a.attrname | a.attr | b.val |
|---|---|---|
| ID | id | |
| 品名 | name | つや姫 |
| 写真 | photo | tsuyahime.jpg |
| 種別 | type | 穀物 |
| 説明 | desc | 庄内産のつや姫です。 |
| 説明 | desc | 今年度産 5kg 包装です。 |
| 参考情報 | info | デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。 |
a.attr='id' は、cards_s、cards_m の属性値ではなく主キーであるため JOIN の結合相手は存在せず空欄になる。
ここでの目標は上記のような表示用の表を得るだけでなく、 表示している各値の修正用の input 要素も生成することである。 上記の表では属性「desc」が2つあり、それらは互いに区別できなければならない。 そのためには既に述べたように、desc 項目の1つ目は desc.1.m、2つめは desc.2.m のように同じ属性でグループ化した場合のグループ内連番を振る必要がある。
| rowid | x |
|---|---|
| 1 | foo |
| 2 | foo |
| 3 | bar |
| 4 | foo |
| 5 | baz |
| 8 | bar |
連番生成は SQL では典型的問題のひとつで、自己結合 を用いて求められる。慣れないうちは複雑に思えるが、 お決まりのパターンで適用できるため熟語を覚える感覚で理解したい。 まずは簡単な例で連番生成してみる。左のような単純な表を作成する。
8つの値を持つテーブルで、x カラムの値が重複した状態で格納されている。 それぞれの x の値が、何個目に登場するものであるかを隣のカラムに出す。 この例では、上から順に {foo, 1}, {foo, 2}, {bar, 1}, {foo, 3}, {baz, 1}, {bar, 2} となる。
このテーブルの作り方を以下に示す。
CREATE TABLE w(x text);
INSERT INTO w VALUES('foo');
INSERT INTO w VALUES('foo');
INSERT INTO w VALUES('bar');
INSERT INTO w VALUES('foo');
INSERT INTO w VALUES('baz');
INSERT INTO w VALUES('bar');
テーブル w に、テーブル w 自身を JOIN で結合する。 結合条件は「カラム x の値が等しい」で行なう。
.head 1 -- ヘッダ表示をON
SELECT L.rowid, L.*, R.rowid, R.* FROM w L JOIN w R
ON L.x=R.x;
rowid|x|rowid|x
1|foo|1|foo
1|foo|2|foo
1|foo|4|foo
2|foo|1|foo
2|foo|2|foo
2|foo|4|foo
3|bar|3|bar
3|bar|6|bar
4|foo|1|foo
4|foo|2|foo
4|foo|4|foo
5|baz|5|baz
6|bar|3|bar
6|bar|6|bar
結合左側の w を別名 L、右側の別名を R とした。 またカラム値が同じものが複数あるため、個別の値が識別できるよう L、Rともに rowid を出力している。以下の説明では「Lの方の rowid=1 のfoo」を 「L:1:foo」のように表記する。
foo に注目しよう。注目する foo が何番目に登場する foo なのかは以下の性質を利用して決められる。
| L:1:foo | 自身のrowid以下のrowidを持つ結合相手が1つ |
| L:2:foo | 自身のrowid以下のrowidを持つ結合相手が2つ |
| L:3:foo | 自身のrowid以下のrowidを持つ結合相手が3つ |
結合相手の条件として rowid の大小比較を加える。
SELECT L.rowid, L.*, R.*
FROM w L JOIN w R
ON L.x=R.x AND L.rowid>=R.rowid;
rowid|x|rowid|x
1|foo|1|foo
2|foo|1|foo
2|foo|2|foo
3|bar|3|bar
4|foo|1|foo
4|foo|2|foo
4|foo|4|foo
5|baz|5|baz
6|bar|3|bar
6|bar|6|bar
左側の w のすべての要素に対して、 結合相手(R.x)の個数をcount()関数で数える。「Lの要素ごと」なので 「GROUP BY L.rowid」で分類する。
SELECT L.rowid, L.x, count(R.x) COUNT
FROM w L LEFT JOIN w R
ON L.x=R.x AND L.rowid>=R.rowid
GROUP BY L.rowid;
rowid|x|COUNT
1|foo|1
2|foo|2
3|bar|1
4|foo|3
5|baz|1
6|bar|2
count() の結果が連番となる。 出力結果を説明的にするために SQLite3 拡張である printf 関数を利用した。
SELECT L.rowid, printf("%d番目の %s", count(R.x), L.x) ITEM
FROM w L LEFT JOIN w R
ON L.x=R.x AND L.rowid>=R.rowid
GROUP BY L.rowid;
rowid|ITEM
1|1番目の foo
2|2番目の foo
3|1番目の bar
4|3番目の foo
5|1番目の baz
6|2番目の bar
さて、以上の手法を利用して表「表形式出力(1)」の l.attrname の部分に同一項目での連番を付加しよう。連番付加にはテーブルの rowid が必要で、項目見出しの並べ換えには _columns テーブルの rowid が必要なので、リスト「表形式出力を得るSQL(1)」 に各テーブルの rowid の選択も加える。また、連番は cards_s と cards_m それぞれ個別にしなければならないので、_columns.attrmode カラムの値も選択に加え、どちらのテーブルに由来する行かも分かるようにする ('P'、'S' または 'M' がそれに相当)。
一時表.1 リスト
/* _columnsテーブルでのrowid、由来テーブル、cards_? でのrowid、
属性表示名、属性、値、の6値を選択 */
SELECT a.colid, a.attrmode, b.rid, a.attrname, a.attr, b.val
FROM (SELECT rowid colid, * FROM _columns) a -- rowidの別名を colid に
LEFT JOIN
(SELECT rowid rid, * FROM cards_s WHERE id='item001'
UNION ALL /* cards_* の rowid には rid と別名を付与 */
SELECT rowid rid, * FROM cards_m WHERE id='item001') b
ON a.attr=b.key
ORDER by colid;
問い合わせの出力は以下のとおり(表形式で示す)。
| a.colid | a.attrmode | b.rid | a.attrname | a.attr | b.val |
|---|---|---|---|---|---|
| 1 | P | ID | id | ||
| 2 | S | 9 | 品名 | name | つや姫 |
| 3 | S | 10 | 写真 | photo | tsuyahime.jpg |
| 4 | S | 11 | 種別 | type | 穀物 |
| 5 | M | 8 | 説明 | desc | 庄内産のつや姫です。 |
| 5 | M | 16 | 説明 | desc | 今年度産 5kg 包装です。 |
| 6 | M | 9 | 参考情報 | info | デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。 |
これで項目ごとの連番を振る準備ができた。 上記の問い合わせを WITH 句で一時的なビュー getall とする。そのうえで getall の 由来テーブル/rowid での連番付与操作を行なう。
WITH getall AS (
SELECT a.colid, a.attrmode, b.rid, a.attrname, a.attr, b.val
FROM (SELECT rowid colid, * FROM _columns) a -- rowidの別名を colid に
LEFT JOIN
(SELECT rowid rid, * FROM cards_s WHERE id='item001'
UNION ALL /* cards_* の rowid には rid と別名を付与 */
SELECT rowid rid, * FROM cards_m WHERE id='item001') b
ON a.attr=b.key
ORDER by colid /* この枠囲み部は「一時表.1 リスト」と同じ */)
SELECT l.colid, l.attrmode, l.rid, l.attrname, l.attr, count(l.rid) seq, l.val
FROM getall l LEFT JOIN getall r
ON l.attr=r.attr AND l.attrmode=r.attrmode AND l.rid>=r.rid
GROUP BY l.attr, l.rid
ORDER BY l.colid;
枠外の部分が連番つきの表を得るために書き足した部分で、 出力は以下のようになる(表形式)
| colid | attrmode | rid | attrname | attr | seq | val |
|---|---|---|---|---|---|---|
| 1 | P | ID | id | 0 | ||
| 2 | S | 9 | 品名 | name | 1 | つや姫 |
| 3 | S | 10 | 写真 | photo | 1 | tsuyahime.jpg |
| 4 | S | 11 | 種別 | type | 1 | 穀物 |
| 5 | M | 8 | 説明 | desc | 1 | 庄内産のつや姫です。 |
| 5 | M | 16 | 説明 | desc | 2 | 今年度産 5kg 包装です。 |
| 6 | M | 9 | 参考情報 | info | 1 | デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。 |
「SQLite3 によるバイナリデータの出し入れ」で示したように、 バイナリデータは16進文字列を経由して出し入れできる。 ここでは、cards_s テーブルの bin カラムに入っている画像バイナリデータを 画像として表示させる。このとき、データベースに入れた画像そのままでは 画素数的に大きすぎる可能性があるので、縮小してサムネイル表示する。
たとえば、上記の出力例の cards_s 由来の rid=10 の行を考える。 attrname='写真'、val='tsuyahime.jpg' のときの bin カラムに大きさ不明(たいていサムネイルにするには大きすぎ)の画像バイナリデータが 格納されているとする。 この場合、以下の手順でサムネイルに相応しい画像に変換する。 convert(ImageMagick)
ここで、%hex とはバイナリデータを16進文字列化したものを 1バイトずつ %xx の形で列挙したものである。たとえば、文字列 "ABCD" (ASCIIコードが16進数で 0x41、0x42、0x43、0x44 の並び)の %hex は %41%42%43%44 である。また、Content-Type の部分は 画像データの Content-type が入る。ここでは単純化するため画像は JPEG 形式のみとし、その場合の Content-type は「image/jpeg」である。 一般的には file コマンドを利用して
file --mime-type File
とすることで得られるのでそれを利用する。
以上の手順を具体化したものを以下に示す(cgilib2 中の hexise、unhexize、escape 関数を参照している)
#!/bin/sh
mydir=`dirname $0`
DB=${1:-db/cgi.sq3} . $mydir/cgilib2-sh
htmlhead 画像一覧
echo '<table border="1">'
echo '<tr><th>filename</th><th>Image</th></tr>'
percent() sed 's/\(..\)/%\1/g'
imgsrcdata_icon() {
printf "<img src=\"data:image/jpeg,"
unhexize | convert -resize '150x150>' -define jpeg:size=150x150 - jpeg:- |
hexize | percent
echo '">'
}
query<<EOF |
SELECT hex(val), hex(bin) FROM cards_s
WHERE val IS NOT NULL AND bin IS NOT NULL;
EOF
while IFS='|' read val bin; do
cat<<-EOF
<tr><td>$(escape `echo "$val"|unhexize`)</td>
<td>`echo "$bin"|imgsrcdata_icon`</td></tr>
EOF
done
echo '</table></body></html>'
この処理の要点は以下のとおりである。
val, bin カラムを取り出すときはいずれも hex() 関数を介して行なう。bin カラムだけでなく val も16進文字列にするのは、 値にどんな不規則な文字(SPC文字など)があっても、後続するシェルの read で、正常に単語分割できるようにするためである。
区切り文字(IFS)を '|' に設定して read で2つのカラムの値を受け取る。
val の値は unhexize() で元の文字列に戻してから escape() でHTMLエスケープしたものを出力する。
bin の値は unhexize() で元のバイナリ(画像データ)に戻してから convert コマンドで縮小する。-resize '150x150>' と最後に不等号をつけることで、元々 150ピクセルより小さい画像はそのままにする。
縮小した画像データをまた hexize() で16進文字列化し、さらに percent() で %hex 文字列にする。
%hex 文字列を <img src="data:image/jpeg,%hex"> の書式に括る。
val、bin カラムからの変換値2つをHTMLのtable要素の1行分のタグで 括って出力する。
最初の項目に記したように、ユーザからの入力値を含むカラムを read で受け取るときには、値に区切り文字が混入することを回避するために hex() 出力で受け取るのが効果的である。
上記 out-icon.cgi で、あらかじめいくつかのデータを含むデータベースの画像をダンプさせた 出力例を以下に示す。
画像一覧
filename Image akiduki.jpg hitomebore.jpg tsuyahime.jpg
上記サムネイル出力と連番つき出力を組み合わせる。 利用者に提示する形式に近いものとするため、カラムIDなどは出力しない。 代わりに、値提示のすぐ脇に、 その値を初期値とした入力フォームを出すものを作成する。
#!/bin/sh
mydir=`dirname $0`
. $mydir/cgilib2-sh
if [ -n "$1" ]; then # 第1引数にIDを受けてそのIDの情報を表出力する
id=`echo "$1"|sed "s/'/''/g"`
rowid=`query "SELECT rowid FROM cards WHERE id='$id';"`
fi
if [ -z "$rowid" ]; then
htmlhead "Not Found"
echo "<p>表示したいidを指定してください。</p></body></html>"
exit 0
fi
htmlhead "$idの情報"
cond="WHERE id='$id'"
percent() sed 's/\(..\)/%\1/g'
imgsrcdata_icon() {
printf "<img src=\"data:image/jpeg,"
unhexize | convert -resize '150x150>' -define jpeg:size=150x150 - jpeg:- |
hexize | percent
echo '">'
}
echo '<table border="1">'
query<<-EOF |
WITH getall AS (
SELECT a.*, b.rid, b.val, b.bin
FROM (SELECT rowid colid, * FROM _columns) a
LEFT JOIN
(SELECT rowid rid, * FROM cards_s $cond
UNION ALL /* cards_* の rowid には rid と別名を付与 */
SELECT rowid rid, * FROM cards_m $cond) b
ON a.attr=b.key
ORDER by colid
) /* 次の行のSELECTの値がシェルスクリプト read に渡る */
SELECT lower(l.attrmode) am, l.rid, l.attr, l.vtype, l.option,
l.attrname, count(l.rid) seq, hex(l.val), hex(l.bin)
FROM getall l
LEFT JOIN getall r
ON l.attr=r.attr AND l.attrmode=r.attrmode AND l.rid>=r.rid
GROUP BY l.attr, l.rid
ORDER BY l.colid;
EOF
while IFS="|" read am rid attr vtype opt kname seq hval hbin; do
val=$(escape "`echo $hval|unhexize`") # 16進値を元に戻してHTMLエスケープ
[ x"$am" = x"m" ] && kname=$kname$seq # 多値テーブルの場合のみ連番付与
[ x"$attr" = x"id" ] && val=$id # idは属性値ではない
printf '%s' "<tr><th>${kname}</th><td style=\"white-space: pre;\">"
if [ -n "$hbin" ]; then # binカラムに値が来たらサムネイルを
echo "$hbin" | imgsrcdata_icon
else
echo "$val"
fi
echo "</td><td>" # 値提示tdここまで/次は入力フォーム出力td
name="$attr.$seq.$am" # input名は 属性.連番.由来テーブル で決める
op="${opt:+ }$opt" # 入力フォームへのオプション文字列
case $vtype in # vtypeに応じたタグを出力
"text") echo "<input name=\"$name\" value=\"$val\"$op>" ;;
"image") echo "<input name=\"$name\" type=\"file\"$op>" ;;
"select") echo "<select name=\"$name\">"
for i in $opt; do
[ x"$i" = x"$val" ] && ck=' checked' || ck=""
echo "<option$ck>$i</option>"
done
echo "</select>"
;;
"textarea") echo "<textarea$op>$val</textarea>" ;;
esac
echo "</td></tr>"
done
echo "</table></body></html>"
これまで説明したしくみによる組み立てなので、 詳細はスクリプト中のコメント文を参照されたい。この CGI スクリプトに有効な特産物IDを指定した結果の例を以下に示す。
tsuyahimeの情報
ID tsuyahime tsuyahime
品名 つや姫 つや姫
写真 
種別 穀物 説明1 庄内産のつや姫です。 庄内産のつや姫です。
説明2 今年度産 5kg 包装です。 今年度産 5kg 包装です。
参考情報1 デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。 デビュー以来連続特Aのつや姫です。 この比類なきうまさとつやをお試しあれ。
最終的にはCSS3の機能を用いて、「値表示」、「値修正用フォーム」、 「削除」、「新規入力用フォーム」を動的に選択表示するデザインと変えて行くが、 これはその一歩手前のものである。
シェルスクリプトの実行速度は、他のスクリプト言語に比べても遅い部類である。 それゆえSQLと組み合わせる場合は、出力構造の組み立てをできるだけ SQL の世界で行ない、シェルが出力の整形に介在する比率をできるだけ小さくしておくのが効率的である。 シェルスクリプトの実行速度に比べるとSQL問い合わせの速度は圧倒的なので、 問い合わせに多少無駄があってもシェルスクリプトシステムでは有意な影響は出ない。 しかしながら将来的に規模の大きいものを扱う必要が出てきたときに、 問い合わせの効率が重要性を帯びてくる。
たとえば直前のリストの thumb-table.cgi で発行している問い合わせを大きな流れで見ると以下のようになる。
WITH getall AS (
SELECT 欲しいカラム
FROM _column テーブルからの値(C)
LEFT JOIN
cards_sテーブルからの値(S)
UNION ALL
cards_mテーブルからの値(M)
)
SELECT 欲しいカラム
FROM getall LEFT JOIN getall
……
ORDER BY _columusテーブルでのrowid;
ここで、_column テーブル、cards_s テーブル、cards_m テーブルからの値をそれぞれ C、S、M とし、一時ビュー getall を G で表し、SQLの集合演算を算術演算の類推で +(UNION)、×(JOIN) で表してみる。すると上記のSQL文は以下のようになる。
G = C×(S+M)
G×G
Gに関する自己結合G×Gは展開すると{C×(S+M)}×{C×(S+M)}になり、C も自己結合の対象に含まれる。しかしながら、C つまり _columns テーブルは項目見出し(attrname)と見出しの出力順(rowid)を決めるために必要なものである。 つまり、3つ組の表からすべての値を和集合で取り出す getall の段階ではCは必須でない。したがって、SQL文全体は以下の流れでも支障ない。
G = S+M
C×G×G
これを問い合わせ文に直したものを示す。
_columnsはあとでJOIN
WITH getall AS ( -- getall = S + M のみにする
SELECT rowid rid, * FROM cards_s $cond -- $condの部分はシェル変数値
UNION ALL
SELECT rowid rid, * FROM cards_m $cond -- $condの部分はシェル変数値
)
SELECT c.attrmode, a.rid, c.attr, c.vtype, c.option, c.attrname, a.seq, val
FROM _columns c
LEFT JOIN
(SELECT l.rid, l.key, count(l.rid) seq, l.val
FROM getall l LEFT JOIN getall r
ON l.key=r.key AND l.rid>=r.rid
GROUP BY l.key, l.rid) a
ON c.attr=a.key
ORDER BY c.rowid;
2つの問い合わせを比較してみる。比較は問い合わせの文の直前に 「EXPLAIN」または「EXPLAIN QUERY PLAN」を前置して得られる実行計画や ドットコマンド「.stats ON」で得られる統計情報を見ることで可能である。 ここでは、簡潔な情報の得られる .stats の結果の一部を示す。 7件のレコードを登録したデータベースからの問い合わせのものである。
| _columnsを先にJOIN | _columnsを最後にJOIN | |
|---|---|---|
| Fullscan Steps | 16 | 10 |
| Sort Operations | 2 | 1 |
| Autoindex Inserts | 16 | 10 |
| Virtual Machine Steps | 1104 | 747 |
結合の順番によってどのような組み合わせ展開が起きるか考慮してみるとよいだろう。
SQLの定石的な問い合わせ文の練習をしておこう。
ある電子掲示板に投稿したユーザと投稿内容を記した以下のようなテーブル postings がある。
| ユーザID(userid) | 発言内容(cmt) |
|---|---|
| taro | あけまして… |
| hanako | おめでとう! |
| honjo | おめでとう! 今年もよろしくね。 |
| taro | こちらこそよろしく! |
| honjo | いまどこ? |
| taro | 初詣きてる |
| honjo | えほんとに? |
| hanako | どこなの |
| taro | honjoんちの近くの |
| honjo | 待ってすぐ行くわ |
| yuza | おいらも! |
このテーブルから、各ユーザによる各発言時の通算発言回数(連番)を求める SQL 文を作成せよ。上記の例であれば以下のような結果が得られるものとする。
.header ON
SELECT 問い合わせ;
ユーザID|回数|コメント
taro|1|あけまして…
hanako|1|おめでとう!
honjo|1|おめでとう! 今年もよろしくね。
taro|2|こちらこそよろしく!
honjo|2|いまどこ?
taro|3|初詣きてる
honjo|3|えほんとに?
hanako|2|どこなの
taro|4|honjoんちの近くの
honjo|4|待ってすぐ行くわ
yuza|1|おいらも!
| ユーザID(userid) | 氏名(name) |
|---|---|
| taro | 公益太郎 |
| hanako | 飯森花子 |
| honjo | 本荘由利 |
| yuza | 遊佐佳麗 |
なお、氏名(name)に重複値があった場合の対処などは考慮しなくてよい。
rowidを利用し、userid カラムが等しいという条件で自己結合を行ない、 rowid が自分自身より小さなものの数を数える。 基本となる問い合わせは以下のようになる。
SELECT a.userid, a.rowid, b.rowid, a.cmt
FROM postings a JOIN postings b
ON a.userid = b.userid AND a.rowid >= b.rowid;
userid|rowid|rowid|cmt
userid|rowid|rowid|cmt
taro|1|1|あけまして…
hanako|2|2|おめでとう!
honjo|3|3|おめでとう! 今年もよろしくね。
taro|4|1|こちらこそよろしく!
taro|4|4|こちらこそよろしく!
honjo|5|3|いまどこ?
honjo|5|5|いまどこ?
taro|6|1|初詣きてる
taro|6|4|初詣きてる
taro|6|6|初詣きてる
honjo|7|3|えほんとに?
honjo|7|5|えほんとに?
honjo|7|7|えほんとに?
hanako|8|2|どこなの
hanako|8|8|どこなの
taro|9|1|honjoんちの近くの
taro|9|4|honjoんちの近くの
taro|9|6|honjoんちの近くの
taro|9|9|honjoんちの近くの
honjo|10|3|待ってすぐ行くわ
honjo|10|5|待ってすぐ行くわ
honjo|10|7|待ってすぐ行くわ
honjo|10|10|待ってすぐ行くわ
yuza|11|11|おいらも!
この結果の a.userid の数を数えればよいが、 どのカラム値ごとに集約するかを考えて GROUP BY を指定する。
1の結果と users テーブルの JOIN で得られる。
SELECT a.userid "ユーザID", count(a.userid) "回数", a.cmt コメント
FROM postings a JOIN postings b
ON a.userid = b.userid AND a.rowid >= b.rowid
GROUP BY a.cmt ORDER BY a.rowid;
最終出力は postings テーブルの rowid で並べ換える。
SELECT u.name "氏名", "回数", "コメント"
FROM users u JOIN
(SELECT a.rowid, a.userid, count(a.userid) "回数", a.cmt コメント
FROM postings a JOIN postings b
ON a.userid=b.userid AND a.rowid>=b.rowid
GROUP BY a.cmt) c
USING(userid) /* ON u.userid = c.userid でもよい */
ORDER BY c.rowid;
これも発言順どおり出力されるよう postings テーブルの rowid で並べ換えることに注意する。
ある試験の結果を記録した以下のようなテーブルがある。
| ユーザID(userid) | 得点(pt) |
|---|---|
| taro | 59 |
| hanako | 95 |
| honjo | 61 |
| yuza | 61 |
得点の高い順に順位付けした表を出力する SQL 文を作成せよ。 上記の例では以下のような出力となる。
SELECT 問い合わせ;
1|hanako|95
2|honjo|61
2|yuza|61
4|taro|59
socres テーブルで自己結合を用い、 あるユーザの得点より高い得点を持つ者を数える。まず、 「自分より得点が高い」という条件で結合した結果を見る。
.head 1
SELECT * FROM scores a JOIN scores b
ON a.pt < b.pt;
userid|pt|userid|pt
taro|59|hanako|95
taro|59|honjo|61
taro|59|yuza|61
honjo|61|hanako|95
yuza|61|hanako|95
これだと首位の人の条件に当てはまる行がないので出てこない。 すべての userid について出力されるよう左結合にしてみる。
SELECT * FROM scores a LEFT JOIN scores b
ON a.pt < b.pt;
userid|pt|userid|pt
taro|59|hanako|95
taro|59|honjo|61
taro|59|yuza|61
hanako|95||
honjo|61|hanako|95
yuza|61|hanako|95
この結果から順位を導き出すには、いずれかのカラムの値ごとに数えた数に 1を足せばよい。
ヒントにある自己左結合の結果の、右側のuseridを数えると以下のようになる。
SELECT count(b.userid), a.userid, a.pt
FROM scores a LEFT JOIN scores b ON a.pt < b.pt
GROUP BY a.userid;
count(b.userid)|userid|pt
0|hanako|95
1|honjo|61
3|taro|59
1|yuza|61
この集計結果に1を足したものが順位である。 得点の高い順にまとめれば求める結果となる。
SELECT 1+count(b.userid) RANK, a.userid, a.pt
FROM scores a LEFT JOIN scores b
ON a.pt < b.pt
GROUP BY a.userid
ORDER BY a.pt DESC;
RANK|userid|pt
1|hanako|95
2|honjo|61
2|yuza|61
4|taro|59

