(4) 10/19の授業内容:t検定
[1] 導入
あなたは公益軒の経営者である。公益軒では最近カレーラーメンをメニューに加え、好評な売り上げを得るにいたっている。しかし、カレーラーメンを注文する人は年配の人が多く、若者への評判はいまいちな気がする。一方、ライバルのカンカンラーメンは若者もカレーラーメンを注文しているようである。カンカンのカレーラーメンが若者に人気があるとすれば、若者は情報網を持っているため、人気が一気に拡大する可能性がある。
果たして若者は、公益軒とカンカンのカレーラーメンの味をそれぞれどの程度好んでいるのであろうか。両者の評価が異なるのかを調べるため、駅の改札を通る若者を10人ごとに1人選び出して調査を依頼した。1人目は公益軒、2人目はカンカン、3人目は公益軒というようにして、順番に割り当てていき100点満点で味を採点してもらった。このようにしてそれぞれの店のカレーラーメンについて8人ずつのデータを取った。
| 公益軒 | 点数 | カンカン | 点数 |
| 1 | 70 | 1 | 85 |
| 2 | 75 | 2 | 80 |
| 3 | 70 | 3 | 95 |
| 4 | 85 | 4 | 70 |
| 5 | 90 | 5 | 80 |
| 6 | 70 | 6 | 75 |
| 7 | 80 | 7 | 80 |
| 8 | 75 | 8 | 90 |
| 平均 | 76.88 | 平均 | 81.88 |
| 分散 | 46.61 | 分散 | 55.86 |
平均値の差を見ると5点近くある。やはり公益軒のカレーラーメンは若者に対してうけがよくないのであろうか。
[2] 母平均の信頼区間を踏まえて差を検討する
[3] 差の信頼性区間の考え方
[4] 実際に差の信頼区間を求めてみる
[5] 差の信頼性区間の解釈
[6] 指標tの性質
さて、公益軒とカンカンのカレーラーメンの味の評価に有意な差があるかどうかを決める方法を考えていこう。このためには前回説明した仮説検定の考え方を用いる。
- まず、「公益軒とカンカンのカレーラーメンの味の評価には差がない」という帰無仮説を立てる。
- 差がないという仮説を立てた場合、今回の測定値の平均値の差は偶然に発生したことになるので、この差が偶然に発生する確率を求める。
- 確率に基づいて、帰無仮説を採択するか、棄却するかを決める。
- 帰無仮説を採択した場合は、有意差(意味のある差)はないと結論を下す。
- 帰無仮説を棄却した場合は、対立仮説が採択され、差がないとは言えない、つまり有意差(意味のある差)があると結論づける。
前回、名義尺度の分析を行う際には、期待度数と観測度数のずれをχ2乗値という指標で表現した。今回は距離尺度の平均値の比較である。距離尺度や比率尺度において2つの母集団の平均値に差があるかどうかを検討する場合t検定が用いられる。
まず2つの母集団A、Bを考える。AもBも大体正規分布にしたがっており、平均値が等しく、分散もほぼ等しいとする。その2つの母集団A、Bそれぞれからa個、b個の標本を取り出してくる。それを標本集団a、bとする。
標本集団a、bの平均値をそれぞれ計算して、それを標本平均a、bとする。
標本平均aと標本平均bの差を計算する。すると、これは0に近い場合が多いと考えられる。なぜなら、もともとの母集団A、Bの平均値が等しいからである。そこから取り出した標本集団a、bの平均値も近い値になることが多いことが推測される。
そこで、次のような指標tを考える。
t=(標本平均の差)/(標本平均の差の標準誤差)
すると、このtは自由度(a+b-2)のt分布に従う。標本平均の差の標準誤差は、上で説明したように、次の式で推定する。
標本平均の差の標準誤差=sqrt((母集団Aの分散/aの標本数)+(母集団Bの分散/bの標本数))
ここで、aとbの母分散は等しいとして、「推定母分散」と表記すると、
差の標本標準誤差=sqrt((推定母分散/標本数a)+(推定母分散/標本数b))
=sqrt(推定母分散×((1/標本数a)+(1/標本数b))
推定母分散は次の式で推定する。これは標本標準偏差を求める方法と同じで、平均からの偏差の平方和(これは分散を求めるときの((データ−平均値)の2乗)の総和のことです)を(標本数−1)で割ったものに相当する。
推定母分散=(標本aの平均からの偏差の平方和+標本bの平均からの偏差の平方和)/((標本数a−1)+(標本数b−1))
まとめると、
t=(標本平均の差)/sqrt(推定母分散×((1/標本数a)+(1/標本数b))
となる。
[7] 指標tを計算してみよう
それでは実際に、公益軒とカンカンのカレーラーメンの評価点について、tを計算してみよう。
まず、標本平均の差は、
標本平均の差=76.88-81.88
=-5.00
次に、差の標準誤差を求める。
公益軒の評価点の標本分散=49.61
その平均からの偏差の平方和=49.61×8
カンカンの評価点の標本分散=55.86
その平均からの偏差の平方和=55.86×8
推定母分散=(49.61×8+55.86×8)/((8-1)+(8-1))
=60.27
差の標本標準誤差=sqrt(60.27×((1/8)+(1/8)))
=3.88
そうすると、tはこうなる。
t=-5.00/3.88
=-1.29
練習:表計算ソフトを用いて公益軒とカンカンの例についてt値を求めてみよう
[8] t分布表を見る
さて、t=-1.29となった。この値はどのくらいの確率で起こるのだろうか。
それを調べるためには、t分布表を使用する。
t分布は自由度によって少しずつ変化する。t検定の場合は、(標本数a-1)と(標本数b-1)を足したものが自由度になる。この場合、標本数aも、標本数bも8だったので、(8-1)+(8-1)で、自由度は14になる。
それでは、t分布表の自由度14のところを見てみよう。
| 自由度 | 有意水準5% | 有意水準1% |
| 1 | 12.706 | 63.657 |
| 2 | 4.303 | 9.925 |
| 3 | 3.182 | 5.841 |
| 4 | 2.776 | 4.604 |
| 5 | 2.571 | 4.032 |
| 6 | 2.447 | 3.707 |
| 7 | 2.365 | 3.499 |
| 8 | 2.306 | 3.355 |
| 9 | 2.262 | 3.250 |
| 10 | 2.226 | 3.169 |
| 11 | 2.201 | 3.106 |
| 12 | 2.179 | 3.055 |
| 13 | 2.160 | 3.021 |
| 14 | 2.145 | 2.977 |
| 15 | 2.131 | 2.947 |
| 16 | 2.120 | 2.921 |
| 17 | 2.110 | 2.898 |
| 18 | 2.101 | 2.878 |
| 19 | 2.093 | 2.861 |
| 20 | 2.086 | 2.845 |
| 21 | 2.080 | 2.831 |
| 22 | 2.074 | 2.819 |
| 23 | 2.069 | 2.807 |
| 24 | 2.064 | 2.797 |
| 25 | 2.060 | 2.787 |
| 26 | 2.056 | 2.779 |
| 27 | 2.052 | 2.771 |
| 28 | 2.048 | 2.763 |
| 29 | 2.045 | 2.756 |
| 30 | 2.042 | 2.750 |
| 40 | 2.021 | 2.704 |
| 60 | 2.000 | 2.660 |
| 120 | 1.980 | 2.617 |
| ∞ | 1.960 | 2.576 |
自由度14において、有意水準5%のtは2.145、有意水準1%のtは2.977と書いてある。これは次のことを意味している。
自由度14のときのt分布を描いてみると、tが2.977よりも大きい、または-2.977よりも小さいことが起こる確率が1%未満であるということを示している。
また、tが2.145よりも大きい、または-2.145よりも小さいことが起こる確率が5%未満であるということを示している。
tが2.977よりも大きい、または-2.977よりも小さい部分を、1%有意水準での棄却域と呼ぶ。
同様に、tが2.145よりも大きい、または-2.145よりも小さい部分を、5%有意水準での棄却域と呼ぶ。
[9] t検定の考え方
いま、有意水準を5%に設定したとすると、tが2.145よりも大きいか、-2.145よりも小さければ(棄却域に入っている)、それが起こる確率は5%未満なので、2つの母集団の平均、つまり公益軒とカンカンの評価点の平均には差がないとした帰無仮説が棄却される。この結果、公益軒とカンカンの評価点の平均には差がないとはいえない、つまり、差があるということになる。
さて、計算したtは、-1.29だったので、5%有意水準での棄却域には入っていない。したがって帰無仮説は棄却できず、結論としては、公益軒とカンカンの評価点の平均には差がないということになる。
[10] t検定の種類
今回の事例では公益軒のラーメンを食べた人と、カンカンラーメンを食べた人が異なっているが、場合によっては同じ人が両方のラーメンを食べることもありうる。同じ人が両方食べた場合は、どちらか一方のみ食べた場合と比較して、個人差の影響が少なくなることが考えられる。このためt検定を行う際に簡易式を用いることができる。
異なる人がいずれかの条件に割り当てられている場合は対応のないt検定が適用される。一方、同じ人が両方の条件に参加している場合は対応のあるt検定が行われる。
対応がないt検定(データ数が等しくない場合)
- Xバー:平均値
- n:標本数(データ数)
- s2:母分散(VARPまたはSTDEVの2乗)
- σ2:標本分散(VARまたはSTDEVの2乗)
- 自由度:n1+n2-2
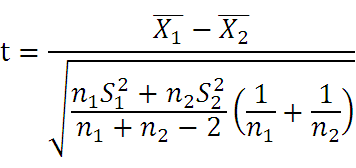
または
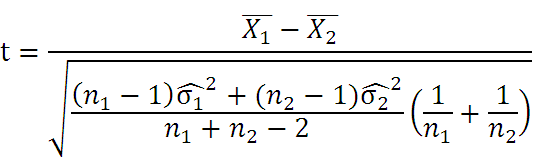
対応がないt検定(データ数が等しい場合)
- Xバー:平均値
- n:標本数(データ数)
- s2:母分散(VARPまたはSTDEVの2乗)
- σ2:標本分散(VARまたはSTDEVの2乗)
- 自由度:n1+n2-2

または
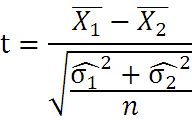
対応のあるt検定
- Dバー:差の平均値
- n:標本数(データ数)
- σ:標本標準偏差(STDEV)
- 自由度:n-1
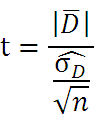
[11] 練習問題
新製品のチーズラーメンの味の点数について、それぞれ8名ずつ得点をたずねてみた。この点数を使ってt検定をしてみよう(公益軒とカンカンではそれぞれ別の人に採点を求めている)。
| 公益軒 | 点数 | カンカン | 点数 |
| 1 | 80 | 1 | 75 |
| 2 | 75 | 2 | 65 |
| 3 | 80 | 3 | 80 |
| 4 | 95 | 4 | 85 |
| 5 | 90 | 5 | 75 |
| 6 | 80 | 6 | 80 |
| 7 | 85 | 7 | 80 |
| 8 | 90 | 8 | 70 |
t検定を実施して結論を導き出すための手順は以下の通りである。順番に実施してみよう。
- 帰無仮説を立てる
- 対立仮説を立てる
- t値を計算する
- 自由度を求める
- t分布表を調べる
- 計算したt値と表の値を比較する
- 結論を述べる
結果の記載方法
レポート等でt検定を実施した結果を記述する場合、記載すべき項目が定められている。以下に例を示すので、今後レポートを作成する際には参考にしよう。
表○は、カンカンラーメンと公益軒のカレーラーメンの味についてそれぞれ8名評価を求めた結果である。t検定の結果、両店の味には有意な差はみとめられなかった(t(14)=-1.29, n.s.)。
なお、t(14)の(14)は自由度をあらわす。
有意:偶然に発生した差ではなく意味の有る差であるという意味
[12] 練習問題2
以下は、8人の若者の協力を得て、公益軒とカンカンの激辛プリンを食べ比べてもらい、双方について得点をつけてもらった結果である。
| 評価者 | 公益軒 | カンカン |
| 1 | 90 | 95 |
| 2 | 75 | 80 |
| 3 | 75 | 80 |
| 4 | 75 | 80 |
| 5 | 80 | 75 |
| 6 | 65 | 75 |
| 7 | 75 | 80 |
| 8 | 80 | 85 |
t検定を実施して結論を導き出すための手順は以下の通りである。順番に実施してみよう。
[13] t検定が適用できない場合
t検定は距離尺度および比率尺度において、2条件の有意差の有無を検討するための検定手法である。式は2種類であり、2条件のデータに対応がある場合(同じ人が両方の条件に参加している場合)と対応がない場合(各条件に異なる人が割り当てられている場合)で使い分けを行う。
以下のような場面ではt検定を用いることができないので注意する必要がある。
- 2条件以上の平均値の差の検定を行う場合:例えばカンカンと公益軒と、来々軒のラーメンの味を比較する場合。
- 2条件の標準偏差が等しいとみなせない場合:公益軒は評点のバラツキが大きいが、カンカンは全員80点の場合等。
3条件以上の平均値の差の検定を行う場合は分散分析という手法を使用する。また2条件の標準偏差が等しいとみなせない場合はウェルチの法によるt検定を実施する。2条件の標準偏差が等しいとみなせるかどうかは、F検定を実施して判断する。
[14] レポート課題
以下の2問を解きなさい。
(1)夏休みに語学研修を行った。効果を調べるために研修前と研修後にテストを実施した。以下がテストの点数である(20名分)。語学研修は効果があったといえるだろうか。
| 学籍番号 | 研修前 | 研修後 |
|---|---|---|
| c120001 | 68 | 78 |
| c120002 | 71 | 72 |
| c120003 | 86 | 93 |
| c120004 | 65 | 63 |
| c120005 | 59 | 64 |
| c120006 | 62 | 65 |
| c120007 | 80 | 79 |
| c120008 | 63 | 68 |
| c120009 | 65 | 72 |
| c120010 | 63 | 73 |
| c120011 | 66 | 67 |
| c120012 | 58 | 65 |
| c120013 | 58 | 69 |
| c120014 | 56 | 62 |
| c120015 | 64 | 73 |
| c120016 | 65 | 79 |
| c120017 | 65 | 63 |
| c120018 | 65 | 71 |
| c120019 | 63 | 72 |
| c120020 | 61 | 61 |
(2)以下は上級プログラミングで行われた中間テスト(50点満点)のクラス別の受講者の得点である。AクラスとBクラスでは成績に差があるといえるだろうか。
| Aクラス | 12 | 26 | 35 | 18 | 43 | 25 | 26 | 37 | 19 | 28 | 36 | 24 | 29 | 23 | 30 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bクラス | 23 | 35 | 28 | 49 | 37 | 30 | 26 | 45 | 29 | 33 | 41 | 38 | 25 | 34 | 33 | 42 |
2つの問題について、以下の流れで検定を行い結果をまとめなさい。1〜8まですべてエクセルファイル内に記載すること。体裁は自由とするがそれぞれの問題に対する回答を1つのワークシートに読みやすくまとめること(合計でワークシートは2つ使用する)。
- 帰無仮説を立てる
- 対立仮説を立てる
- 自由度を求める
- t値を計算する
- t分布表を調べる
- 計算したt値と表の値を比較する
- 結論を述べる
提出要領
- To: naoya @ e.koeki-u.ac.jp(@前後のスペースを除去すること)
- Subject: 社会情報処理(4)
- 提出期限:次回授業開始時まで
- ファイルを添付して送ること。ファイル名は学籍番号-shakai4.xls
自主課題
ウェルチの法によるt検定と、F検定の方法について調べてみよう。