(9)06/15の授業内容
- 正規表現のパターンをキーボードから入力
- reg = STDIN.gets.chomp!
- expression = Regexp.new(reg, true, "e")
- if expression =~ line
- 正規表現の指定方法(追加)
- 正規表現を用いた成績処理
- if /(\S+)\s+(\d+)\s+(\d+)/ =~ line
- name[n] = $1, eng[n] = $2.to_i, jap[n] = $3.to_i
正規表現を作るためには,正規表現として扱いたいパターンを//でくくって示します
/パターン/
この方法はプログラムの中に直接記述することができるので,特定のパターンのみを検索するプログラムであれば,一番簡単な方法になります.しかし,前回行った課題のように任意のパターンにマッチする文字列を検索するというような場合は,毎回プログラムの内容を書き換えなければならないため面倒です.
今回はキーボードから正規表現のパターンを入力できるようにプログラムを変更します.そのためには,もう1つの正規表現の指定方法をまず把握する必要があります
a= Regexp.new("Ruby")
これはRubyを正規表現のパターンとし,それのパターンをaに代入するという表記方法です.これをまず確認してみよう
#!/usr/koeki/bin/ruby
a = Regexp.new("Ruby")
p a
このプログラムをreg.rbという名前をつけて保存し,実行してみよう.pは配列の格納状況を調べることができるメソッドと説明しましたが,正規表現のパターンがどのようになっているかを調べることもできます.このプログラムを実行すると
/Ruby/
と表示されることが確認できましたか? つまりRegexp.new("Ruby")は()内を正規表現のパターンに変更してくれます.ここではRubyというように具体的なパターンを入力していますが,具体的なパターンを入力するかわりに変数を入れることもできます.つまり,キーボードから入力したパターンを読み込み,適当な変数に代入し,ここでRubyとする代わりにその変数名を指定すれば,キーボードからの入力によりパターンを自由に指定することが可能になります.この考えに基づき,前回のプログラムを変更してみましょう(黄色が変更箇所です)
#!/usr/koeki/bin/ruby STDERR.print "検索パターンは?:" reg = STDIN.gets.chomp! expression = Regexp.new(reg, true, "e") while line=gets if expression =~ line print line end end
続いてプログラムの変更点について解説します
キーボードから入力された値を改行をとりregという変数に代入します.文字列のままでよいので.to_iはつけません.STDINがついていますが,これは標準入力という意味です.データを読み込む場合,キーボード入力の読み込みと,既存のファイルからの読み込みを考えることができます.標準的にはキーボードの入力が使用されます(標準入力といいます).今回のプログラムでは検索するリストを外部ファイルから読み込み,かつ検索パターンをキーボードから読み込みます.つまり,入力元が2種類あります.Rubyプログラムを実行する場合にファイルを指定すると,getsはそのファイルを読み込んでしまうため,この行が読み込む入力元はファイルではなく,標準入力であるキーボードから読み込むことをあらわすSTDINを入れる必要があります
先ほどは()の中にRubyという文字列を入れていましたが,ここではregという変数を入れています.reg以外にtrueやeがありますが,これらの意味は下記のとおりです
第2引数
true:大文字と小文字を区別してほしくない場合./パターン/iと同じ意味
false:大文字と小文字を区別してほしい場合
第3引数(日本語の検索をしたいときに指定)
"e":EUCコードで書かれているものとして照合./パターン/eと同じ意味
"s":Shift-JISコードで書かれているものとして照合./パターン/sと同じ意味
101/102教室で英数字を検索する場合
Regexp.new(変数, true)
Regexp.new(変数, false)
101/102教室で日本語を検索する場合
Regexp.new(変数, true, "e")
Regexp.new(変数, false, "e")
/sai?to/iと決め打ちをしていたのが,expressionという変数に置き換えられています.オプションのiは2つ上の行で指定しているのでここでは指定しません
練習
このプログラムをkensaku2.rbという名前をつけて保存し,先週の課題で作成したリストを用いて自由に検索をしてみよう
[ぁ-ん]:ひらがな全部.「ぁ」は小文字(laもしくはxaと入力)
[亜-腕]:漢字全部(ただし第一水準のみ)
下記のような成績リストを考えてみよう.左が英語で右が国語のテストの得点とする.ここから各テストの平均点を算出してみよう
まず,下記の成績リストをscore.txtとして保存する
丘本秋子 45 60 高梁缶 52 34 仁科牧子 80 45 藤嶌楓 71 67 伊井利郎 66 50 木之元週一 90 82 多村数馬 49 56 砂糖真琴 55 70 藤嶋丸子 82 68 嶋田多香子 74 49 齋藤由 63 56 高橋麹 92 71 渡部すず 59 48 渡辺勇次 69 77 藤島真希 70 65
続いて以下のプログラムをscore.rbとして保存する
#!/usr/koeki/bin/ruby
#初期設定
name=[] #名前を代入する配列
eng=[] #英語の得点を代入する配列
jap=[] #国語の得点を代入する配列
n=0 #配列に値を代入する際に使用するインデックス
sum_eng=0 #英語の合計得点
sum_jap=0 #国語の合計得点
#成績の読み込みと合計得点の算出
while line = gets
if /(\S+)\s+(\d+)\s+(\d+)/ =~ line
name[n] = $1
eng[n] = $2.to_i
jap[n] = $3.to_i
sum_eng += eng[n]
sum_jap += jap[n]
n += 1
end
end
#平均値の算出と表示
av_eng = sum_eng/n
av_jap = sum_jap/n
printf "英語の平均は%3.1f点,国語の平均は%3.1f点です\n", av_eng, av_jap
print "\n"
#個人個人の得点の表示
i=0
print "-- 氏名 -------- 英語 -- 国語 \n"
print "\n"
while i < n
printf "%-10s \t %3d \t %3d\n", name[i],eng[i],jap[i]
i += 1
end
このプログラムで新しく出てきたのは下記の2行です
\S:空白以外にマッチ
\s:空白にマッチ
\d:0から9までの数字とマッチ
+:1回以上の繰り返しにマッチ
():*+?と組み合わせて繰り返しで使うと前回は説明しましたが,ここでは後方参照のために利用しています
後方参照とは
後方参照というのは,正規表現でマッチした部分の一部を取り出す方法です.正規表現の中の()でくくられた部分にマッチした文字列を,()の順番に応じて$1,$2といった$数字の形の変数で取り出すことができます
#!/usr/koeki/bin/ruby /(.)(.)(.)/ =~ xyz first = $1 second = $2 third = $3 print first,"\n" #=> x print second,"\n" #=> y print third,"\n" #=> z
$1,$2,$3は上の行の正規表現の3つの()に対応しています(後方参照).1つ目は(\S+)ですから,空白以外の文字の1回以上の繰り返しを表し,ここでは氏名に該当します.そして氏名を文字列として配列nameに代入しています.nameのインデックスは初期値が0のnとし,whileの繰り返しの中でn+=1で値を1ずつ増加しています.
1つ目と2つ目の間の\s+は空白の1回以上の繰り返しで,その後の(\d+)は数字の1回以上の繰り返しです.これは英語の得点に該当します.英語の得点は.to_iメソッドを使って文字列から整数に変換され,engという配列に代入されます.同様に$3は国語の得点を表し,japという配列に代入されます
課題
score.rbを改良する.改良の方法は下記の1〜3であり,これらのうち,いずれかを選んで実施する.改良したプログラムおよびその説明,実行結果についてレポートする.なお,改良を行ううえで,1がもっとも易しく,3がもっとも難易度が高い.このため,1を選んだ場合は8点満点,2は9点満点,3は10点満点で採点する
- プログラムの最後の個人得点の 表示において,得点のみでなく平均値との差を表示するように改良する. この際の並び順は,英語の得点,平均との差,国語の得点,平均との差と する.この課題では下から3行目のprintfの行のみ書き変えればよい
- score.txtの英語,国語の得点の横に数学の得点を入れ(値は適当でよい),3つの課題の得点をもとに,上記1と同様の改良を行う.つまり,プログラムの最後の個人得点の表示において,英語の得点,平均との差,国語の得点,平均との差,数学の得点,平均との差の6つを表示するよう変更する.この課題では正規表現のパターンの変更,数学の個人得点,合計得点,平均用の変数が必要になる
- 上記1と同様に,最後の個人得点の表示において平均値の差を表示するのに加え,偏差値も表示するようプログラムを改良する.結果表示の際の並び順は,英語の得点,平均との差,偏差値,国語の得点,平均との差,偏差値とする.この課題を選んだ場合はscore.txtに数学の得点を追加する必要はない.この課題に関してはヒントは出さない.偏差値の計算方法のみ下記に示す
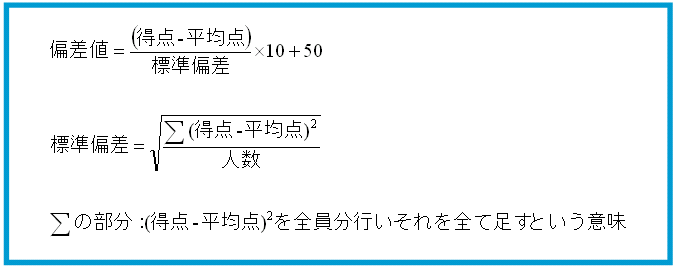
平方根(ルート)の計算は下記を参考にすること(Math::sqrt(数字)の部分で実際の計算を行っている)
#!/usr/koeki/bin/ruby
x = 9
a = Math::sqrt(x)
print a,"\n" #=>3.0と表示される
作成したプログラム,実行結果をメールでnaoya@e.koeki-u.ac.jp宛に送る.
課題の提出期限は6月18日(土)17:00まで
メール送信時の注意
- Subjectは「学籍番号-kadai7」とすること
- 本文の1行目ではまず名乗ること
- 2行目以降は下記の構成で記載すること
- 作成したプログラム
- プログラムの各部の説明
- 実行結果
- 感想
今回は作成したプログラム,プログラムの各部の説明に同じウェイトをおいて評価します
Tips
emacsについて
- emacsで新しいファイルを作成する場合は,C-x C-fを押し,ミニバッファにkensaku/kadai2.rbのようにファイル名を入力する
- ファイルの保存はC-x C-s
- 日本語入力のオンオフの切り替えはC-o
Mewについて
- emacsを起動する
- Escとxを押し,mewと入力しReturn(Escとxを押すことを,一般にM-xと表記します)%<--これでMewが起動します
- Mewを起動するとパスワードがたずねられるので入力しReturn
- 新着メールの確認およびパスワードを間違えた場合はiと入力しReturn
- メールを読む場合は,カーソルキー(矢印キー)で読みたいメールを選びReturn
- メールの新規作成はwと入力
- e-mailの本文にテキストファイルを読み込むには,新規送信メール画面の本文を記入するエリアにカーソルを移動し,Ctrl+x,iとすると,ミニバッファにInsert file: ~/と表示されるので,読み込みたいファイル名を入力する。
- プログラムの実行結果の貼り付けは,kterm上の出力結果部分をマウスで選択し,Mewの本文の貼り付け位置にカーソルを移動し,マウスの真ん中ボタンをクリックする
- メールの送信はC-c C-cと入力するか,もしくはメニューのsendアイコンをクリックする
- Mewを終了するにはqと入力
- emacsを終了する