(11)06/29の授業内容
trr試験
授業開始20分後から開始します(2限は11:00,3限は13:20).テキストは日本国憲法で,制限時間は20分間.この時間内にマークした最高得点を評価対象とします
- 2進数と16進数
- 2進数と10進数の変換
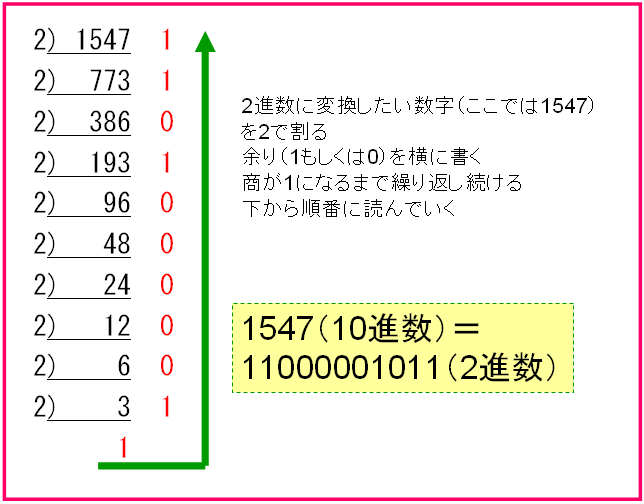
- 10進数を2進数へ
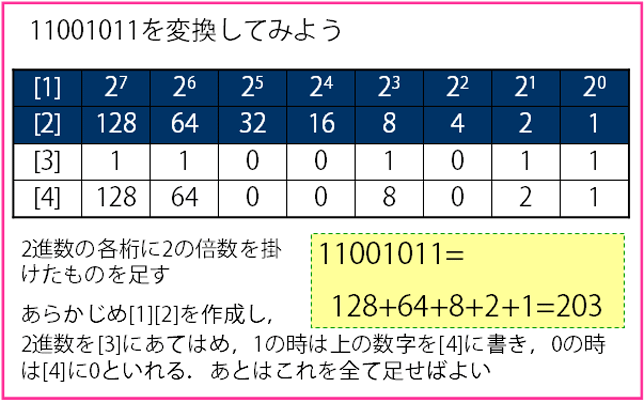
- 2進数を10進数へ
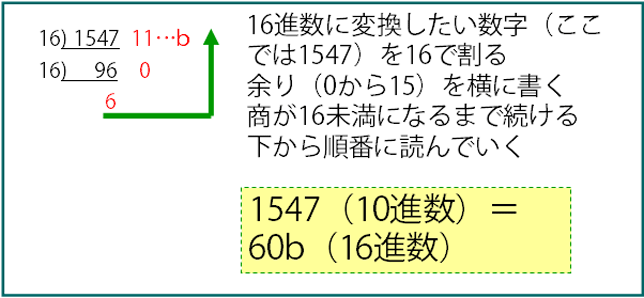
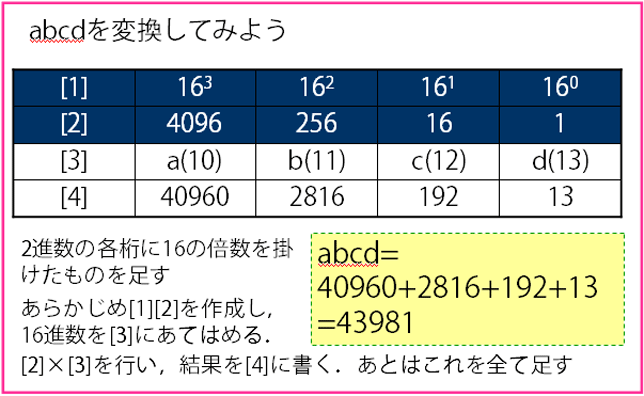
- 16進数と10進数の変換
- 10進数を16進数へ
- 16進数を10進数へ
- Rubyでの取り扱い
- ASCIIコード
- 0x00 NUL:空文字(文字列の終端をあらわすことが多い)
- 0x07 BEL:端末のベルを鳴らす
- 0x08 BS:バックスペース
- 0x09 HT:タブ
- 0x0A LF:改行
- 0x1B ESC:エスケープ
- 文字列と文字コード
- 文字コードに対応する文字を出力
- 文字に対応する文字コードを出力
コンピュータの内部では,文字も数字も全て1と0の2進数で保存されています.1と0の2種類の情報であればスイッチのオン/オフや,磁極の向き,光の点滅で表現することが可能です.私たちが日常的に使用している10進数をコンピュータでそのまま取り扱うことを考えた場合,10種類の情報の表現方法を考えなければならず,装置の複雑化,大型化をまねくことになります
2進数は0と1だけを使用しますので,0の次は1,1の次は1桁繰り上がって10になります.下記に10進数との対応表を示します
| 2 進 数 | 10 進 数 | 16 進 数 |
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 10 | 2 | 2 |
| 11 | 3 | 3 |
| 100 | 4 | 4 |
| 101 | 5 | 5 |
| 110 | 6 | 6 |
| 111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | 10 | a |
| 1011 | 11 | b |
| 1100 | 12 | c |
| 1101 | 13 | d |
| 1110 | 14 | e |
| 1111 | 15 | f |
| 10000 | 16 | 10 |
Rubyでは,数値の先頭につける記号で何進法かを指定します
接頭語なし:10進数(例えば,10,25)
接頭語0b:2進数(例えば,0b1001,0b111101)
接頭語0x:16進数(例えば0x1a1,0xf)
なお,何進数で指定しても一旦読み込まれれば,全て10進数で取り扱われます.出力する際に何進法とするかは,printfの書式制御文字によって指定可能です
%d:10進数
%b:2進数
%x:16進数
コンピュータ内では文字は1と0の組み合わせで管理されている.この数字と文字の対応表のことを文字コードといいます
半角英数字は,数字,大文字小文字のアルファベット,?#$%などの記号により構成され,2進数8桁である8ビットで表現されます(ただし先頭の1桁は使用していないので実際には7桁).半角英数字の文字コートをASCIIコードといいます.一方日本語は漢字が含まれるため8ビットでは表現できず,16ビットで表現されます.文字コードはJIS,Shift-JIS,EUCが代表的です.1種類ではないため,使用する環境により文字化けが生じることがあります.Webページを見ていてへんな文字列が表示されるのは,htmlファイルを作成した際の文字コードと,閲覧しているときの文字コードが異なるためです.作成者は文字コードとして何を利用しているかhtmlファイル内に記載する必要があるのですが,書き間違えるとこうした現象が生じます
ASCIIコードの表は下記の通りです.この表では16進数での文字コード表記になっています.2進数で書いてもかまいませんが,桁数が多くなるため表が大きくなってしまいます
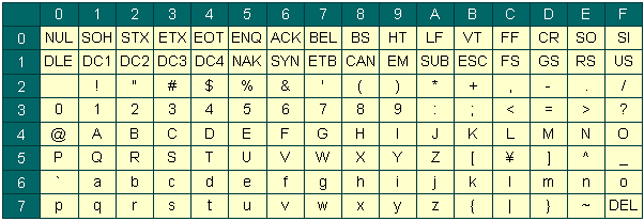
行方向(左側)が10の位,列方向(上側)が1の位になります.例えば,Aは41になります.Rubyでは16進数は0xをつけるのでAは0x41になります
0行と1行(0x00〜0x1F)は制御文字をあらわします.主に端末のコントロールをするもので代表的なものは下記の通りです
%c:printfの書式制御文字の%cは,文字コードに対応する文字を出力します
printf "%c", 0x07
とすると,文字コード0x07すなわちBELが出力され,端末のベルがなります
特定の文字の文字コードを知るためには?文字とします.例えばプログラム中で?Qとすれば,それはQの文字コード(0x51)を書いたのと同じことになります
これをprintfの制御文字である%x(16進数)で表示すれば,対応する文字コードがあきらかになります
しかし,この方法では1文字の文字コードを調べるのは簡単でも,文字列を構成する各文字の文字コードを調べるのはやや面倒です
文字列"Koeki"を構成する"K""o""e""k""i"の各文字の文字コードを調べることを考えてみましょう.ここでは配列のときと同じように[]を利用すると簡単に取り出すことができます
printf "%x\n", "Koeki"[i]
上記のようにインデックスにiを使用し,初期値を0とした上で,whileの繰り返しの中でiの値を1ずつ変更していけば構成する文字の文字コードを全て明らかにすることができます.もちろん下記のように文字列を変数に代入してもかまいません
a = "Koeki"
printf "%x\n", a[i]
課題
以下の5つの問から実施したいものを選んで実施する
- 0x1f8b(16進数),0b110011010(2進数)を10進数に変換せよ(計算過程を示すこと)(各1点)
- 0x135 + 0x67の計算を行った結果を10進数,2進数,16進数で示せ(計算過程を示すこと)(各1点)
- 自分の誕生日の西暦年,月,日を全部足した数を2進数と16進数に直せ(計算過程を示すこと)割り算は)と-を駆使して書くこと(各1点)
- ローマ字で書いた自分の名前の文字列を全て文字コード (16進数)で表記せよ(1点)
- キーボードから入力した任意の半角英数字で構成される文字列を文字コード(16進数)に変換して出力するプログラムを作れ(2点)
作成したプログラム,実行結果をメールでnaoya@e.koeki-u.ac.jp宛に送る.
課題の提出期限は7月2日(土)17:00まで
メール送信時の注意
- Subjectは「学籍番号-kadai9」とすること
- 本文の1行目ではまず名乗ること
- 2行目以降は下記の構成で記載すること
- 問1の計算過程と回答
- 問2の計算過程と回答
- 問3の計算過程と回答
- 問4の計算過程と回答
- 問5のプログラム
- プログラムの説明
- 実行結果
- 感想
問1〜4は計算過程が示されていない場合は減点対象とします
Tips
emacsについて
- emacsで新しいファイルを作成する場合は,C-x C-fを押し,ミニバッファにkensaku/kadai2.rbのようにファイル名を入力する
- ファイルの保存はC-x C-s
- 日本語入力のオンオフの切り替えはC-o
Mewについて
- emacsを起動する
- Escとxを押し,mewと入力しReturn(Escとxを押すことを,一般にM-xと表記します)%<--これでMewが起動します
- Mewを起動するとパスワードがたずねられるので入力しReturn
- 新着メールの確認およびパスワードを間違えた場合はiと入力しReturn
- メールを読む場合は,カーソルキー(矢印キー)で読みたいメールを選びReturn
- メールの新規作成はwと入力
- e-mailの本文にテキストファイルを読み込むには,新規送信メール画面の本文を記入するエリアにカーソルを移動し,Ctrl+x,iとすると,ミニバッファにInsert file: ~/と表示されるので,読み込みたいファイル名を入力する。
- プログラムの実行結果の貼り付けは,kterm上の出力結果部分をマウスで選択し,Mewの本文の貼り付け位置にカーソルを移動し,マウスの真ん中ボタンをクリックする
- メールの送信はC-c C-cと入力するか,もしくはメニューのsendアイコンをクリックする
- Mewを終了するにはqと入力
- emacsを終了する