(9)11/16·11/30の授業内容
- ハッシュの活用
- リテラル配列(これまで利用してきた方法)
- Array.new
- 配列の連結(+)
- 配列末尾への破壊的要素追加(<<)
- 配列の破壊的結合(concat)
- 要素を順番に取り出す(each)
- 指定要素の発見(index(val))
- 配列の長さを返す(lengthもしくはsize)
- 配列を結合して文字列化(join(sep))
- 末尾への破壊的追加(push(val1,val2,...))
- 末尾要素の取り出し(pop)
- 配列の逆順への並び替え(reverse)
- 配列の逆順への並び替え(破壊的)(reverse!)
- 先頭要素の取り出し(shift)
- 先頭への要素の追加(unshift(val))
- 重複要素の削除(uniqとuniq!)
- 小さい順に並び替える(sort)
- sortメソッドによる並べ替え
- 本格的なデータ処理
- ドロー系ソフトTgifを使ってみよう
- 左ボタン → オブジェクトの選択
- 中ボタン → 編集機能全般メニュー(上に並ぶメニューの統合版)
- 右ボタン → 作図メニュー(tgifウィンドウ左のものと同じ)
- グリッド (Alt-d, Alt-i)
- カット・コピー (C-x, C-v)
- グループ・アングループ (C-g, C-u)
- プリントアウト (C-p)
- 保存 (C-s)
ハッシュは、keyとvalueを使用して任意の値に任意の値を結びつけ、ペアでデータを保存することができるものでした。では、次のようなデータ(dodgeball.txt)にハッシュを適用する場合、どうしたらよいでしょうか。
氏名 勝ち 負け ドリームス 10 2 クイーンズ 4 8 ブラックス 6 6 オスカーズ 3 9 コウエキズ 9 3 ヒロインズ 12 0
上記は、プロドッジボールリーグであるDリーグの勝敗表です。これをハッシュに代入しようとすると、どうしたらよいか戸惑うことになります。key「ドリームス」のvalueが「10と2」という2つの値になっているためです。
実はハッシュのvalueには文字や数字だけでなく、配列や、さらにハッシュを代入することができます。つまり
dodge["ドリームス"] = [10, 2]
のように代入することもできます。これを利用すると勝率を求めるプログラムは以下のようになります(dodgeball.rb)。
#!/usr/koeki/bin/ruby
dodge = Hash.new
while line = gets
if /(\S+)\s+(\d+)\s+(\d+)/ =~ line
# 1個目の() (\S)→チーム名が入る
# 2個目の() (\d)→勝ち数が入る
# 3個目の() (\d)→負け数が入る
dodge[$1] = [$2.to_f, $3.to_f] # 配列を代入
end
end
print "--チーム名------------+-勝ち-+-負け--+-勝率---\n"
for team, result in dodge
# result には、[勝ち数, 負け数] という配列が入っている
win = result[0] # resultの第0要素が勝ち数
lose = result[1] # resultの第1要素が負け数
printf("%-20s %5d %5d %4.3f\n", team,
win, lose, win/(win+lose))
end
ruby dodgeball.rb dodgeball.txt --チーム名------------+-勝ち-+-負け--+-勝率--- ヒロインズ 12 0 1.000 コウエキズ 9 3 0.750 ブラックス 6 6 0.500 クイーンズ 4 8 0.333 オスカーズ 3 9 0.250 ドリームス 10 2 0.833
配列と違いハッシュでは、値を取り出すときの順番は入れたときの順番とは無関係になります。配列は順番にデータを格納する場合に都合がよいといえます。ハッシュはkeyを使ってvalue取り出すことができるので、データベースとして有効です。なお、ハッシュではmd5(Message Digest 5)という方法で、得られたデータを暗号化してしまいこみます。暗号化されたデータの大きさによって取り出される順番が決まるため、代入した順番と取り出した順番が異なることがあります。
ちなみにこのプログラムを配列で書くと以下のようになります(dodge-hairetsu.rb)。
#!/usr/koeki/bin/ruby
team = [] #チーム名用の配列
win = [] #勝ち数用の配列
lose = [] #負け数用の配列
i = j = 0 #配列のインデックス
while line = gets
if /(\S+)\s+(\d+)\s+(\d+)/ =~ line
# 1個目の() (\S)→チーム名が入る
# 2個目の() (\d)→勝ち数が入る
# 3個目の() (\d)→負け数が入る
team[i] = $1
win[i] = $2.to_f
lose[i] = $3.to_f
i += 1
end
end
print "--チーム名------------+-勝ち-+-負け--+-勝率---\n"
while j < i
printf("%-20s %5d %5d %4.3f\n", team[j],
win[j], lose[j], win[j]/(win[j]+lose[j]))
j += 1
end
ruby dodge-hairetsu.rb dodgeball.txt --チーム名------------+-勝ち-+-負け--+-勝率--- ドリームス 10 2 0.833 クイーンズ 4 8 0.333 ブラックス 6 6 0.500 オスカーズ 3 9 0.250 コウエキズ 9 3 0.750 ヒロインズ 12 0 1.000
配列生成(参考)
Rubyでは配列やハッシュを利用することで、多くのデータを処理するプログラムを手軽に作ることができます。ここでは、配列に対する操作メソッドを示します(一部は前期に説明したものです)。
プログラム中に書く「具体的な値」のことをリテラルと言います。リテラル配列では、具体的な値をカンマで区切って書きます。
a=[100,60,20,"xyz"]
は、aが要素として1、2、3、xyzを含む配列であることを意味しています。
決まった長さのものを、決められた値で埋めつくした初期配列を作ることもできます。これにはArray.newを使用します。配列変数を数多く作る場合や配列内の要素が多い場合は、リテラル配列を使用していちいち入力するのは面倒なので、Array.newが使われることが多くなります。
a=Array.new(長さ)
a=Array.new(長さ,初期値)
例えば、a=Array.new(5)の場合は、[nil,nil,nil,nil,nil]
のように各要素の初期値がnilの配列が生成されます。
a=Array.new(5,10)の場合は
[10,10,10,10,10]という配列が生成されます。
配列処理メソッド(参考)
配列に備わるメソッドのうち、有用なものを選んで説明します。以下の説明では変数aに、配列[50,20,80,10]が代入されているものとします。
+メソッドは元の配列と別の配列をつなげた新しい配列を返します。
b=[30,90,60]であるとき
c = a + b #=> [50,20,80,10,30,90,60]となります。aとbの値は変わりません。
<<メソッドは、配列の末尾に新しい要素を追加します。元の配列自体が変更します。元の値を直接書き換える操作を破壊的操作と言います。
a << 70
p a #=> [50,20,80,10,70]
引数に指定した配列を元の配列の末尾に破壊的に結合します
b=[30,90,60]であるとき
a.concat(b)
p a #=> [50,20,80,10,30,90,60]となり、配列aの値が変化します。bは変化しません。
配列の中の値である要素を順番に取り出す方法として、eachがあります。
a.each do |i|
〜配列内の要素をiに順番に代入しながら処理を繰り返し実施する
end
これはfor文やwhile文を使用して書くことも可能です。
for文を使用した場合
for i in a
〜配列内の要素をiに順番に代入しながら処理を繰り返し実行する
end
while文を使用した場合
i = 0
while i < a.length
〜iをインデックスとして対応する要素を順次読み出して処理を実行
i += 1
end
配列の中に引数に指定した値valに等しいものがあるか調べ、最初に見つかった位置のインデックスを返します。見つからない場合はnilを返します。
p a.index(20) #=>1
p a.index(70) #=>nil
配列の長さ(要素がいくつあるか)を返します。
p a.length #=>4
p a.size #=>4
配列の各要素の間に文字列sepを挟んで連結した文字列を返します。sepを省略した場合は、そのまま各要素が連結されます
p a.join("/") #=>"50/20/80/10"
p a.join #=>"50208010"
配列の末尾に引数で指定した要素valを破壊的に追加します。追加する要素は複数指定できます。
p a.push(70) #=>[50,20,80,10,70]
p a.push(90,30) #=>[50,20,80,10,90,30]
p a #=> [50,20,80,10,80,30]
破壊的操作なのでaの値も変化しています。
配列の末尾の要素を取り除き、取り除いた要素の値を返す。要素がない場合にはnilを返す。
p a.pop #=> 10
p a #=> [50,20,80]
p a.pop #=> 80
p a #=> [50,20]
p a.pop #=> 20
p a #=> [50]
p a.pop #=> 50
p a #=> []
p a.pop #=> nil
配列の要素をすべて逆順に並び替えた配列を返します。
a.reverse #=>[10,80,20,50]
p a #=>[50,20,80,10]
破壊的操作ではないのでaの値は変わりません。
配列の要素をすべて破壊的に逆順に並び替えた配列を返します。
p a.reverse! #=>[10,80,20,50]
p a #=>[10,80,20,50]
破壊的操作なのでaの値も変化します。
配列の先頭要素を取り出し、その値を返す。配列はひとつずつ前につめられる
p a.shift #=>10
p a #=>[80,20,50]
p a.shift #=>80
p a #=>[20,50]
p a.shift #=>20
p a #=>[50]
p a.shift #=>50
p a #=>[]
p a.shift #=>nil
破壊的操作なのでaの値も変化します。
配列の先頭にvalを追加し、その配列を返します。各要素はひとつずつ後ろにずれます。
p a.unshift(70) #=>[70,10,80,20,50]
p a #=>[70,10,80,20,50]
破壊的操作なのでaの値も変化します。
配列から重複した要素を取り除き、取り除いた部分を前につめた配列を返す。
c = [10,80,20,50,30,20,50,10,80]
p c.uniq #=>[10,80,20,50,30]
p c #=>[10,80,20,50,30,20,50,10,80]
d = [10,80,20,50,30,20,50,10,80]
p d.uniq! #=>[10,80,20,50,30]
p d #=>[10,80,20,50,30]
uniq!は破壊的操作なのでdの値も変化します。
配列の要素を小さい順(昇順)に並び替えます。
p a.sort #=>[10,20,50,80]
p a #=>[10,80,20,50]
e = ["eagle","shark","panther"]
p e.sort #=>["eagle","panther","shark"]
p e #=>["eagle","shark","panther"]
破壊的操作ではないのでaの値は変化しません。
ソート基準ブロック
配列aに対して、単にa.sortとすると、小さい順(昇順)に並び替えることができました。では大きい順(降順)に並び替えるためにはどうしたらよいでしょうか。一つの方法は、a.sort.reverseです。これにより昇順にソートした後で、逆順に並び替えが行われるので降順での並び替えをしたことになります。
他の方法として、sortの後ろに、ソート基準を決めるブロックを付加するというものがあります。具体的には
配列.sort {|x,y| xとyの比較式}
のように書きます。例えば大きい順(降順)に並べ替えたい場合は、<=>という演算子を使用し
b = a.sort {|x,y| y <=> x}
などとします(xとyの順番に注目)。
この方法を使い、文字列でも並び替えをすることができます。
ring = ["galadriel", "eowyn", "merry", "arwen"]
lord = ring.sort{|a, b| b<=>a}
p lord #=> ["merry", "galadriel", "eowyn", "arwen"]
上記の{|a, b| b<=>a}という部分がソート基準ブロックです。|a, b|は、配列内のデータ(要素)を順次a、bに代入し左側をa、右側をbとすることを意味します。<=>は宇宙船演算子とも呼ばれ、左辺が大きければ1を返し、等しいときは0、右辺が大きいときには-1を返すものです。ここでは、左の方が大きかったら順番はそのまま、右のほうが大きかったら順番を入れ替えるという働きをします。これを配列内の要素について繰り返し行うことで、右側のほうが小さくなるように、つまり大きい順(降順)になるように並び替えを行っています。
ちなみに、単にsortとすると昇順ソートになりますが、これはソート規準ブロックに {|a, b| a<=>b} を指定したのと同じです。sort.reverseと比較をすると複雑ですが、ハッシュのソートを行う際には必要になります。
ハッシュのソート
以下のようなハッシュ、testを得点の低い順に並び替えることを考えてみましょう。
test = {
"一郎" => 72,
"二郎" => 48,
"三郎" => 96,
"五郎" => 33,
}
ハッシュをソートする際は、keyのみを取り出して、それをソートするという考え方で進めます。このためにハッシュからkeyのみを抽出します。ハッシュ.keysでkeyだけを取り出すことができます。
p test.keys #=>["三郎","二郎","一郎","五郎"]
順番は代入時とは異なることがわかります。これをsortメソッドで並び替えます。このとき、並べ替え基準は名前ではなく、得点なので、sortメソッドのソート基準ブロックではvalueを比較します。
p test.keys.sort {|x,y| test[x] <=> test[y]} #=>["五郎", "二郎", "一郎", "三郎"]
これによりkeyは値段の小さい順に並ぶので、valueとペアにして出力すればよいことになります(sort.rb)。
#!/usr/koeki/bin/ruby
test = {
"一郎" => 72,
"二郎" => 48,
"三郎" => 96,
"五郎" => 33,
}
for item in test.keys.sort{|a, b| test[a] <=> test[b]}
printf("%s は %d点です。\n", item, test[item])
end
実行結果は下記の通りです
% ruby sort.rb 五郎は33点です。 二郎は48点です。 一郎は72点です。 三郎は96点です。
ハッシュのソートを使ってデータ処理を行ってみましょう。冒頭で示したdodgeball.txtをもう一度思い出してみよう。さきほどはこのデータをハッシュに読み込み、勝率を算出するプログラムを作成しましたが、結果の表示順はばらばらでした。ここではsortメソッドを使って、勝ち数が高い順に表示することを考えてみましょう。
並び替えるためには、各ハッシュの要素のkeyだけを取り出した上でsortメソッドを使用します。ただし、並べ替えの基準となるのは勝ち数なので、ソート基準ブロックを使用して以下のように設定します。
dodge.keys.sort {|x, y| dodge[y][0] <=> dodge[x][0]}
変数 x, y には、比較対象となるチーム名が入ります。つまり、dodge[x]は、いずれかのチームの勝ち負けの配列(ドリームスなら[10,2])が得られることになります。この配列の0番目の要素が勝ち数なので、dodge[x][0]はチームxの勝ち数ということになります。
そして、dodge.keys.sort {|x, y| dodge[y][0] <=> dodge[x][0]}により、勝ち数の多い順に並び替えたチーム名が得られるので結果は
["ヒロインズ", "ドリームス", "コウエキズ", "ブラックス", "クイーンズ", "オスカーズ"]となります。
このkeyの順番で結果を表示するようにすればよいわけですから、これを踏まえてプログラムを改良すると下記の通りになります(dodge-sort.rb)。
#!/usr/koeki/bin/ruby
dodge = Hash.new
while line = gets
if /(\S+)\s+(\d+)\s+(\d+)/ =~ line
# 1個目の() (\S)→チーム名が入る
# 2個目の() (\d)→勝ち数が入る
# 3個目の() (\d)→負け数が入る
dodge[$1] = [$2.to_f, $3.to_f] # 配列を代入
end
end
print "--チーム名------------+-勝ち-+-負け--+-勝率---\n"
for team in dodge.keys.sort {|a,b| dodge[b][0] <=> dodge[a][0]}
win = dodge[team][0]
lose = dodge[team][1]
printf("%-20s %5d %5d %4.3f\n", team,
win, lose, win/(win+lose))
end
実行結果は以下のようになります
ruby dodgeball.rb dodgeball.txt --チーム名------------+-勝ち-+-負け--+-勝率--- ヒロインズ 12 0 1.000 ドリームス 10 2 0.833 コウエキズ 9 3 0.750 ブラックス 6 6 0.500 クイーンズ 4 8 0.333 オスカーズ 3 9 0.250
起動と終了
ktermで
% tgif &[Retern]
終了はtgif画面でCtrl-qまたは、メニューバーのFileからQuit
メニュー
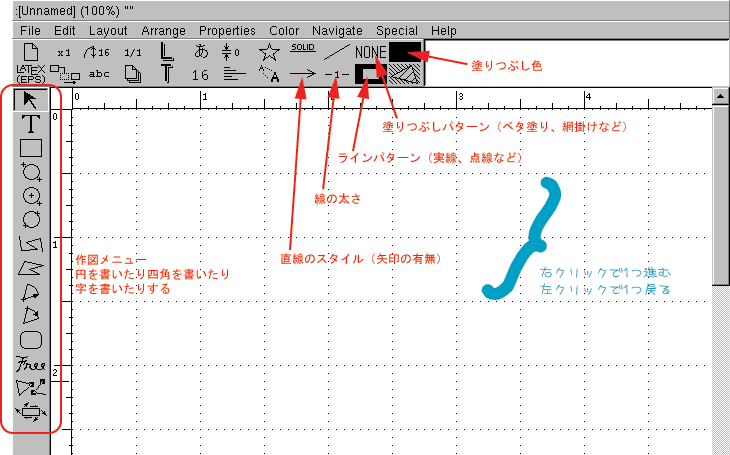
もっと詳しい使い方は、Googleで「tgif 使い方」で検索して調べてみましょう。
日本語の出し方
左側の作図ツールで T (Text)を選び、ドローエリア内で文字を配置した居場所をクリックする。その後でCtrl+SPC を押すと kinput2(日本語入力窓)が起動する。アルファベットを打ってからだと、英語フォントに切り替わってしまって Ctrl+SPC を押しても kinput2 が起きない。うまくいかない場合は、Fontメニューで、RyuminかGothicを選んでから Ctrl+SPC を押す(Fontメニューはドローエリア内でマウスの中ボタンをクリックするとでてくる)
日本語入力のOFFは、SHIFT+SPC
Ctrl+SPCを押したときに
There is no Selection Owner of _JAPANESE_CONVERSION_
というエラーが出るときは、kinput2が落ちている。ktermから
% kinput2 &
とすると、kinput2が使えるようになる。
tgifで作った画像をWebページに掲載する
このためには、画像フォーマットをpngやjpgに変更する必要があります(デフォルトはobj)。FileメニューよりPrint/Export Formatを選び、PNGやJPEGを選択します。この後で、印刷(Ctrl-pもしくはFileメニューからPrint)を選ぶとPNG形式、JPEG形式の画像を出力します。
上記操作を行ったら、ktermでlsして、当該ファイルが新規作成されているかどうか確認しましょう。
課題
以下の問題のうち1題を選んでプログラムを作成し、レポートを提出してください。
- tgifを使って、とっても素敵な絵を描いて送る。この課題を選んだ人は、プログラムを送るかわりに、作成したファイルを添付で送ること(6点だが、感動した場合はさらに良い点がつくこともある)。
- dodge-sort.rbを参考に、負け数の多い順に結果を表示するプログラムを作成してください(7点満点)。
- dodge-sort.rbを参考に、勝率の高い順に結果を表示するプログラムを作成してください。消化試合数が同じ場合、勝率による並び替えと勝ち数による並び替えは同じ結果になってしまうため、勝ち数と負け数を合計した試合数が全てのチームで同一にならないように、適宜dodgeball.txt内の値を書き換えてください(8点満点)。
- dodge-sort.rbをベースにして、dodgeball.txtに引き分け数を追加し、勝ち3点、引き分け1点、負け0点とし、これらを使って計算した勝ち点の大きい順に並び替えるようにプログラムを改良してください(9点満点)。
- dodgeball.txtと同じような書式で、自分の好きな事柄のデータファイルを作成し、データ中の任意の項目で並べ替えた結果が表示できるプログラムを作成してください。データファイルの項目数(valueに該当するデータ数)は3つ以上とすること。なお、任意の項目で並べ替えるとは、プログラムを実行すると「1.安打数、2.打率、3.打点のどれで並べ替えをしますか」などとメッセージを表示し、選んだ番号に基づいて、並べ替えができるものとする(10点満点)。ただし、他の先生のページでサンプルとして提示されているテストの得点や相撲の勝敗以外を取り上げるものとする。
作成したプログラムや実行結果をメールでnaoya@e.koeki-u.ac.jp宛に送る
課題の提出期限は12月06日(火)23:59までです
メール送信時の注意
- Subjectは「学籍番号-1130」とすること
- メール本文は下記の構成で記載すること
- プログラム(メールに貼り付ける)
- プログラムの実行結果
- プログラムの説明
- 感想
- 自由製作課題のメンバーについて
説明のポイント:正規表現と後方参照、for文の中の処理内容、dodge-sort.rbからの改良点について。単にWEBページをコピーペーストしたものは減点対象とする
レポート採点基準:期限内提出(2点)、プログラムの正誤(1〜4点)、説明(3点)、指示通りにメールを送っているか(1点)
参考までにこれまでの自由製作の例を示します(広瀬先生のページ)
http://roy.e.koeki-u.ac.jp/~yuuji/2004/ix/freeprogram/index.html
Tips
emacsについて
- emacsで新しいファイルを作成する場合は,C-x C-fを押し,ミニバッファにkensaku/kadai2.rbのようにファイル名を入力する
- ファイルの保存はC-x C-s
- 日本語入力のオンオフの切り替えはC-o
Mewについて
- emacsを起動する
- Escとxを押し,mewと入力しReturn(Escとxを押すことを,一般にM-xと表記します)%<--これでMewが起動します
- Mewを起動するとパスワードがたずねられるので入力しReturn
- 新着メールの確認およびパスワードを間違えた場合はiと入力しReturn
- メールを読む場合は,カーソルキー(矢印キー)で読みたいメールを選びReturn
- メールの新規作成はwと入力
- e-mailの本文にテキストファイルを読み込むには,新規送信メール画面の本文を記入するエリアにカーソルを移動し,Ctrl+x,iとすると,ミニバッファにInsert file: ~/と表示されるので,読み込みたいファイル名を入力する。
- プログラムの実行結果の貼り付けは,kterm上の出力結果部分をマウスで選択し,Mewの本文の貼り付け位置にカーソルを移動し,マウスの真ん中ボタンをクリックする
- メールの送信はC-c C-cと入力するか,もしくはメニューのsendアイコンをクリックする
- Mewを終了するにはqと入力
- emacsを終了する